How Can I Handle Anti-Scraping Measures on Websites?
Web scraping is one of the most effective ways to collect and analyze data at scale. But if you’ve tried it for any length of time, you’ll know it’s not always smooth sailing. Websites don’t always welcome automated traffic. Some want to protect server resources, others are guarding sensitive data, and plenty just don’t want bots in the mix. That’s why they deploy a wide range of anti-bot mechanisms to detect and block scrapers.
So how can you keep your scrapers running without constant bans and blocks? The key is twofold:
- Prevention first: Avoid triggering anti-bot systems in the first place.
- Bypass when necessary: Have strategies ready when a site actively pushes back.
This guide breaks down the most common defenses, explains how to avoid triggering them, and shows you how to bypass them when necessary.
What is Anti-Scraping?
Anti-scraping refers to the collection of techniques and technologies websites use to stop automated scraping. It’s essentially the opposite of web scraping: while scrapers try to extract data, anti-scraping systems work to stop it.
This is a classic cat-and-mouse game:
- Scrapers upgrade their scraping scripts and infrastructure.
- Websites upgrade their anti-bot technologies to detect scraping activities more accurately.
- Both sides adapt in an ongoing cycle.
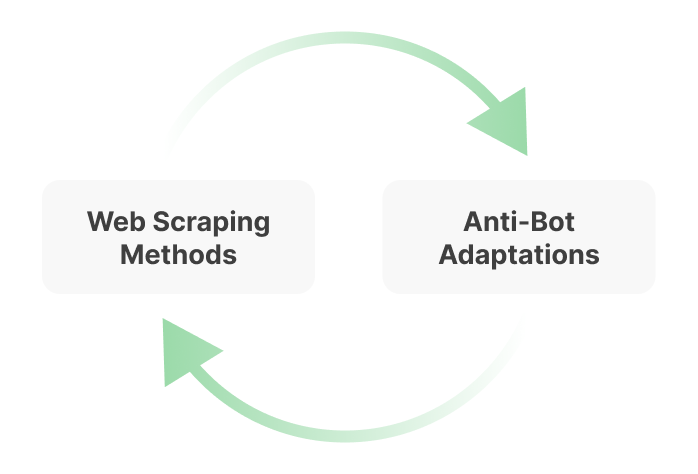
The key takeaway: you don’t want to brute-force your way through anti-scraping tools. The best approach is to avoid detection entirely by making your traffic appear to come from a normal human user browsing web pages in a web browser.
The Most Common Anti-Scraping Measures (And How to Handle Them)
Let’s look at the defenses you’re most likely to encounter, why website owners use them, and how to handle each one.
1. IP blocking and rate limiting
What it is: Websites track traffic from each IP address. If too many requests come from the same IP address too quickly, the system returns errors such as “429 Too Many Requests” or blocks you altogether.
Why sites use it: To prevent server overload and stop automated scraping.
How to bypass:
- Use proxy services with rotating proxies to distribute requests across multiple IP addresses.
- Employ IP rotation so every request looks like it comes from a different IP address.
- Mix residential proxies (authentic household IPs), ISP proxies (fast and reliable), and data center proxies (scalable).
How to avoid:
- Never send all requests from a single IP address.
- Add randomized delays between requests to mimic human behavior.
- Scrape during off-peak hours to reduce the risk of blocking scrapers.
2. User agent and header checks
What it is: Anti-scraping systems check HTTP headers, especially the user agent header, to confirm whether the request looks like a real browser.
Why sites use it: A missing or fake user agent string is an easy giveaway for bots. Many websites even flag an outdated user agent.
How to bypass:
- Rotate through realistic user agent strings from modern browsers.
- Include supporting headers like Referer, Accept-Language, and Accept-Encoding.
- Ensure your user agent header identifies consistently with the rest of your fingerprint.
How to avoid:
- Keep user agents updated.
- Use rotating user agent strings across sessions.
- Align headers so that they match what a normal web browser would send.
3. Login and Authentication Walls
What it is: Some websites require logins before showing content (common with LinkedIn, Facebook, or premium news sites).
Why sites use it: To protect sensitive data, monetize exclusive content, and keep scraped data behind a paywall.
How to bypass:
- Simulate login flows with headless browsers like Puppeteer or Selenium.
- Reuse cookies from a manual login session.
Note: scraping behind a login often breaks Terms of Service and could be illegal. Always consult legal advice before doing this.
How to avoid:
- Look for public APIs.
- Check if Google cache or other public endpoints provide what you need.
4. JavaScript challenges
What it is: Advanced anti-bot systems use puzzles or page elements that only real browsers can execute.
Why sites use it: Simple scrapers can’t run JavaScript code or fully render web pages.
How to bypass:
- Use headless browsers that can execute JavaScript and render dynamic content.
- Try a web scraping API that handles these challenges for you.
How to avoid:
- If a site relies heavily on JavaScript, don’t use basic HTTP libraries! Upgrade your stack so your scraper can render web pages like a real browser.
5. CAPTCHAs
What it is: Tests that ask users to click images, type distorted text, or solve puzzles to prove they’re human.
Why sites use it: CAPTCHAs block automated bots and protect forms, checkout flows, and logins.
How to bypass:
- Integrate third-party CAPTCHA-solving services (2Captcha, Anti-Captcha).
- Pair solvers with proxy services for higher success.
How to avoid:
- Slow your request rate.
- Randomize request timing.
- Act like a human user to reduce triggers.
6. Honeypots
What it is: Honeypot traps are hidden links or forms in the HTML code that only scraping scripts would interact with.
Why sites use it: To catch bots that parse raw HTML instead of rendered content.
How to bypass:
- Ignore hidden elements (display:none, visibility:hidden).
- Train scrapers to only follow visible, relevant links.
How to avoid:
- Test your scraping process carefully.
- Don’t let naïve scraping scripts click every link on the page.
7. User behavior analysis
What it is: Anti-bot technologies monitor user behavior like scrolling, navigation, and click timing. Bots that don’t mimic human browsing patterns get flagged.
Why sites use it: To separate bots from a real human user.
How to bypass:
- Simulate mouse movements and scrolling. Some scrapers even add random mouse movements or scripts for simulating mouse movements.
- Randomize request order and timing.
How to avoid:
- Program your scraper to mimic human browsing patterns.
- Keep session cookies active to better replicate the appearance of real browsing.
8. Browser fingerprinting
What it is: Websites build a “fingerprint” of your device using screen resolution, OS, fonts, time zone, and plugins.
Why sites use it: Even if you change IP addresses, a unique fingerprint can still identify you.
How to bypass:
- Use anti-detect browsers that spoof fingerprints.
- Rotate viewport sizes, time zones, and other details.
How to avoid:
- Keep fingerprints consistent per session: switching mid-session looks suspicious.
- Use advanced tools that align fingerprints with real-world browsers.
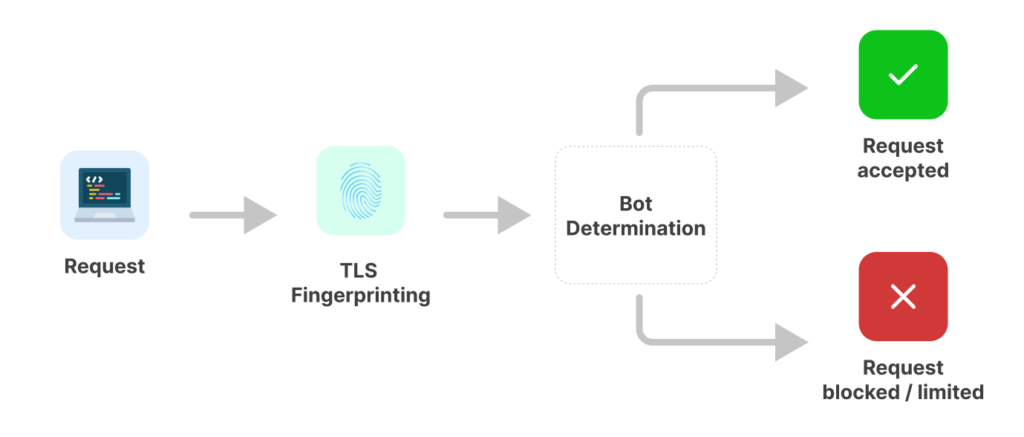
9. TLS fingerprinting
What it is: Fingerprinting based on the TLS handshake during HTTPS connections.
Why sites use it: TLS fingerprinting is harder to fake than headers or user agent strings.
How to bypass:
- Update your libraries (like OpenSSL) so TLS versions and ciphers match common setups.
- Use modern frameworks that automatically spoof TLS details.
How to avoid:
- Don’t let your scraper stand out with an outdated TLS fingerprint.
10. Geo-blocking
What it is: Restricting or blocking content by geography.
Why sites use it: Many websites only serve users from specific countries.
How to bypass:
- Use localized proxies.
- Match headers (Accept-Language) with the target region.
How to avoid:
- Always scrape from IPs in the same region as the site’s typical human users.
How Web Scraping Tools Handle Website Anti-Bot Measures
Building a resilient scraper completely from scratch can be overwhelming. You’d need to manage IP addresses, rotate user agent strings, keep session cookies aligned, and ensure every request looked like it came from a genuine human user. That’s why many developers now rely on modern scraping tools and web scraping APIs, which bundle together multiple solutions for handling anti bot systems automatically.
The Easy Way to Scrape
Our API is fully supported with cookies, user agents and a vast pool of proxies. Turn URLs into raw data easily!

One of the most important features these tools offer is headless browsing. A headless browser can render web pages and execute JavaScript code just like a full graphical user interface, but it runs invisibly in the background. This matters because many websites today don’t serve all their data in static HTML. Instead, the content is dynamically loaded with JavaScript. A simple scraper would see only an empty shell of HTML code, while a headless browser can run the scripts, render the page fully, and extract the same data a real user would see on their screen.
Alongside that, scraping tools usually integrate with proxy services. Proxies are the backbone of bypassing IP blocking, because they allow you to spread requests across many different IP addresses and locations. Instead of sending every request from a single IP address (which quickly gets flagged), a proxy network handles IP rotation for you, making traffic look as if it comes from thousands of human users around the world. Many web scraping APIs let you pick specific geographic regions, which is useful if a site shows different content depending on location.
Another important piece is session and cookie management. Human users don’t start from scratch every time they visit a site; cookies carry over, sessions persist, and browsing patterns look consistent. Without that, your scraper may appear suspicious. Web scraping tools can automatically maintain cookies across requests, so that your scraper mimics natural human browsing patterns instead of behaving like a fresh visitor on every page.
Many platforms include built-in anti-scraping tools to fine-tune headers, fingerprints, and retries. They automatically add realistic HTTP headers, align them with your chosen user agent string, and retry requests in smarter ways when errors occur. This saves you from coding complex logic yourself.
The advantage of using these bundled services is efficiency: instead of piecing together your own infrastructure for every project, you can focus on the scraping process and the data you actually need. The heavy lifting—staying undetected and handling anti-scraping mechanisms—runs in the background.
Best Practices for Avoiding Anti-Scraping Measures
A lot of guides focus on how to “bypass” blocks once you’ve hit them. But the smarter, more sustainable approach is avoiding anti-scraping measures in the first place. Think of it like driving: you don’t want to slam into every red light and figure out a way around, it’s easier to anticipate the signs and steer clear.
The most important best practice is to work with proxy services that handle IP rotation. Sending all your requests from one IP is the fastest way to trigger anti-bot systems. By rotating across many addresses, ideally residential or ISP proxies, you distribute traffic in a way that looks more like real user activity.
Equally important is how you identify yourself. Every request should carry a user agent string, and you’ll want to rotate and update those frequently. Using the same outdated user agent header across thousands of requests looks artificial, while rotating through modern browser versions makes your scraper blend in naturally with real traffic.
Don’t overlook HTTP headers either. Real web browsers send a whole set of headers beyond just the user agent: things like Accept-Language, Referer, and Accept-Encoding. If your scraper only sends the bare minimum, it sticks out immediately. Including realistic headers that match your chosen user agent makes your traffic harder to distinguish from a real human user.
Another golden rule: respect the site’s limits. Websites often respond with 429 Too Many Requests when they feel overloaded. Instead of hammering the server, build in randomized delays between requests and vary your crawling speed. Humans don’t click every link at perfectly regular intervals, so your scraper shouldn’t either.
Finally, remember that just because you can extract data doesn’t mean you should. Focus on the information you genuinely need, keep your web scraping activities ethical, and avoid straining the site’s infrastructure. The best way to keep projects running smoothly long term is to make your scraper indistinguishable from a polite human visitor.
Advanced Methods
Even if you follow best practices, some websites deploy particularly stubborn defenses. In these cases, you may need to reach for more advanced methods that go beyond standard proxies and user agent rotation.
One option is to reverse engineer APIs. Many modern sites rely on background API calls to serve content. By watching your browser’s network traffic in developer tools, you can often identify these requests and replicate them in your scraper. Instead of parsing complex HTML code, you can extract clean JSON data directly from the API. This can dramatically simplify the scraping process while also reducing the need to render heavy web pages.
Another trick is to use Google’s cached version of a page. For static or infrequently updated sites, scraping from the cache can help you bypass tough anti-scraping tools altogether. However, the downside is that the cached data may not always be fresh, and not every site allows its pages to be cached.

For scrapers that need constant new sessions, some turn to Tor routing. Tor changes your IP address automatically every few minutes, making it harder for anti-scraping systems to track you. That said, many websites block known Tor exit nodes, and Tor can be slower than traditional proxy services. It’s best used in combination with other techniques rather than as a standalone solution.
Perhaps the most cutting-edge approach is using adaptive scrapers powered by AI and machine learning algorithms. These systems can detect when a site changes structure, identify new anti bot technologies, and adjust their behavior on the fly. Instead of you manually updating selectors or fingerprints, the scraper adapts itself in real time to keep working.
One of the most underrated tactics is to simulate human behavior as closely as possible. That might mean adding scrolling actions, random pauses, or even mouse movements during browsing sessions. Headless browsers like Playwright or Selenium allow you to program these interactions, which makes your scraper look far more like a real human user and far less like automated scraping.
When you combine these advanced tools with the preventive best practices covered earlier, you give your scraper the best chance of success, even on sites with strong anti bot technologies.
Ethical and Legal Considerations
Web scraping is powerful, but it’s also bound by law. While scraping public information is not inherently illegal, the way you go about it, and what you do with the scraped data, matters a great deal. The legal landscape is constantly evolving, and landmark cases like LinkedIn v. hiQ Labs show just how tricky these issues can be. In that case, hiQ Labs scraped public LinkedIn profiles to build analytics tools, and LinkedIn argued that doing so violated the Computer Fraud and Abuse Act (CFAA). After years of appeals, the courts made it clear that scraping “public” data is not always the same as “authorized” access.
The lesson we learn from this is that scraping exists in a gray area, and website owners have increasing tools (both technical and legal) to fight back.
There are three major legal frameworks to keep in mind:
- CFAA (Computer Fraud and Abuse Act): This U.S. federal law prohibits unauthorized access to computer systems. If you attempt to bypass login walls or scrape private data, you could be in violation.
- DMCA (Digital Millennium Copyright Act): Copyright law applies online too. If you scrape copyrighted text, images, or other content and reuse it without permission, you could run into copyright infringement claims.
- Terms of Service (ToS): Most websites spell out whether scraping is allowed. Even if the law is fuzzy, ignoring ToS can lead to cease-and-desist letters, account suspensions, or lawsuits.
Because the rules vary across jurisdictions and cases, the safest route is always to practice responsible scraping. That means acting in ways that reduce your legal and ethical risks while also respecting the site’s infrastructure and users. Some best practices include:
- Don’t overload servers. Bombarding a site with thousands of requests in seconds can slow down or even crash it, hurting legitimate users. Use rate limits, random delays, and polite scraping speeds.
- Don’t collect sensitive personal information. Even if you technically can scrape it, personal data is often protected by privacy laws like GDPR in Europe or CCPA in California. Avoid scraping anything that could identify individuals without consent.
- Respect robots.txt where possible. While not legally binding everywhere, robots.txt is a widely recognized way for website owners to signal what they do and don’t want crawled. Respecting these signals is good practice and reduces friction.
- Be transparent in how you use data. If you’re building a business on scraped data, consider disclosing where it comes from and ensuring it’s used ethically.
Handled responsibly, web scraping is a legitimate and valuable practice. It powers everything from price comparison tools to academic research. But crossing the line, by ignoring site rules, overloading infrastructure, or collecting private data, can quickly turn a useful tool into a liability. Keeping your scraping process ethical protects you from lawsuits and reputational damage, while still allowing you to gather the web data your project needs.
Best Ways to Bypass Anti-Scraping Techniques Checklist
| Anti-scraping measure | Why it’s used | How to bypass | How to avoid triggering |
|---|---|---|---|
| IP blocking | Stop overload | Rotating proxies | Spread out requests |
| User agents & headers | Spot bots | Rotate user agent strings | Keep headers consistent |
| Login walls | Protect data | Simulate login | Use public endpoints |
| JavaScript challenges | Block bots | Headless browsers | Use scraping tools that can execute JavaScript |
| CAPTCHAs | Stop automated bots | Solver services | Human-like browsing patterns |
| Honeypots | Trap bots | Ignore hidden elements | Avoid naïve scraping scripts |
| Behavior analysis | Detect automation | Simulate mouse movements | Mimic human browsing patterns |
| Browser fingerprinting | Track devices | Anti-detect browsers | Consistent fingerprints |
| TLS fingerprinting | Identify anomalies | Modern libraries | Stay updated |
| Geo-blocking | Enforce regions | Localized proxies | Match headers & location |
Final Thoughts
So, how can you handle anti-scraping measures on websites? The short answer is to avoid first, bypass second.
By using rotating proxies, consistent headers, and mimicking human browsing patterns, you can stay ahead of anti-bot systems. When tougher defenses appear, advanced tools like headless browsers, web scraping APIs, and adaptive scrapers step in.
Scraping isn’t about brute force. It’s about finesse. With the right setup and the right partners, you can keep your scraping process efficient, ethical, and sustainable.
How Rayobyte Can Help
You don’t need to juggle all these scraping measures yourself. Rayobyte provides:
- Residential, ISP, and datacenter proxies with automatic IP rotation.
- Support for rotating user agent strings and managing headers.
- Scalable proxy services so your web scraping activities run smoothly.
- A powerful Web Scraper API that handles everything in the background
With Rayobyte, your requests spread across thousands of IPs, fingerprints, and sessions, making them look like normal traffic from human users. That means less time worrying about anti-scraping technologies, and more time focusing on the scraped data you actually need.
Try our proxies now, or get in touch with our team to find out more.
Ethical Proxies for the Best Results
All our proxies are carefully selected and maintained, giving you both peace of mind and a higher chance of success!