




















The Ultimate Guide To Pulling Data From A Website Into Excel
Web scraping is an excellent way to grab all the information you could ever want from another site. A good web scraping program can collect the data that interests you and deliver it quickly and easily. However, some web scrapers may present the data in a format that you’re not familiar with. For example, many web scraper APIs deliver results in a JSON format that’s not very clear if you don’t understand code.
That’s why you might wonder how to pull data from a website into Excel. Most people are much more familiar with Excel and Google Sheets than they are with JSON. If you can translate those JSON results into an Excel or Google Sheets file, you’ll be able to use these programs’ high-quality data analysis tools to learn from the information you’ve collected.
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, compatible with all automation frameworks.

The translation process is easier than you’d think. In this article, you’ll learn why automated data scraping from websites into Excel is so helpful and how to scrape data from a website into Excel or Google Sheets the right way. Ready to learn more? Let’s dive in.
Why Learn How to Pull Data From a Website Into Excel?

Web scraping allows you to collect huge amounts of data at once. A great web scraper will help you collect the information you’re looking for along with the context surrounding it. This information is important to have, but it’s not always the easiest to read or analyze in its raw state.
With Excel and Google Sheets, web scrapers win new functionality. When the web scraper can send data directly to a CSV file, you can get started with your analysis right away.
For example, an Excel web scraper can send all the information you need directly to the spreadsheet. There, you can:
- Run macros that sort the information
- Find data that matters to you
- Develop visualizations with the click of a button
You can do the same by creating web scraping Google Sheets files. But how do you actually convert web scraper responses into Excel or Google Sheets files? Here’s what you need to know.
Collecting and Understanding the Data

Before you can do anything about sending results from your web scraper to Excel, you need to understand what you’re working with. Every scraper presents results in its own way. Rayobyte’s Web Scraping API, for example, presents results as JSON responses.
In this article, we’ll specifically be looking at the format produced by the Rayobyte’s Web Scraping API API. Furthermore, we’ll be interacting with XPath, which is a language that’s used in Rayobyte’s Web Scraping API to find the HTML and CSS elements you want to collect. As a result, the specific code used in these examples may not be universally applicable. However, the general principles will apply to all scrapers that present JSON responses.
What is a JSON response?
JSON stands for JavaScript Object Notation. It’s a way to store information that’s used by many websites. It’s intended to be a lightweight, human-readable way to communicate data between websites. Since many sites have begun using AJAX (Asynchronous JavaScript And XML) techniques, JSON has taken off.
AJAX techniques help sites load faster by loading asynchronously. JavaScript is used to load information as the visitor needs it. Using JSON is a quick and easy way to make sure that this information is loaded as quickly as possible.
An example of JSON data storage might look like this:
var Maggie = {
"age" : "30",
"hometown" : "New York, New York",
"eyecolor" : "blue"
};
This code does a few things. First, it creates a code object called “Maggie.” Anytime “var Maggie” is referenced, the program will be able to pull up this object. Second, it stores three “properties” about the object “Maggie.” The “key” : “value” pairing repeats three times, storing the properties of “age,” “hometown,” and “eyecolor.”
This is useful for programming since coders can reference the properties of an object by using their name. For instance:
document.write(‘Maggie’s eyes are ' Maggie.eyecolor ‘.‘);
This would output “Maggie’s eyes are blue.”
Similarly, JSON can also store arrays. An array is a collection of objects stored in square brackets. An array may look like this:
“neighbors”:[
{“firstName”:”Maggie”, “lastName”:”Smith”},
{“firstName”:”Peter”, “lastName”:”Parker”},
{“firstName”:”Mickey”, “lastName”:”Mouse”},
]
Both arrays and properties can be useful if you want to scrape data from a website to Excel. The straightforward nature of these responses makes it easy to translate them into tabular form.
What is CSV?
CSV stands for “Comma Separated Values.” It’s a super-simple method for storing spreadsheet data. It’s basically a plain text document that stores information and fills it into your preferred spreadsheet format based on commas and paragraph breaks. CSVs can be read by Excel and Google Sheets alike. A CSV file might look like this:
Neighbor First Name,Neighbor Last Name
Magge,Smith
Peter,Parker
Mickey,Mouse
In a spreadsheet, that would look like this:
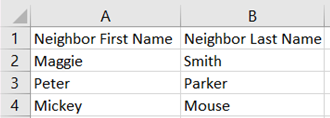
Of course, CSV files can get much longer, but at their core, this is all they are. Converting a JSON file into a CSV file is all about pulling out the information you care about and converting it into this new format.
What is XPath?
XPath is a query language that’s used to find nodes in an XML document. Essentially, XPath can look at sites that run on XML and find specific bits of information. Those bits of information can be found in the HTML or CSS of a site.
The things that XPath is used to find are often called “XPaths,” which can be confusing. In this tutorial, “XPath” will only refer to the language, and “selector” will be used to describe the information you’re looking for.
Elements of the web scraper JSON response
Let’s look at a scrape of iTunes to see how JSON responses look in reality. This scrape is intended to collect a list of track names from the Pearl Jam list of top songs. Let’s see what JSON returns in the scrape.
“{
"status": "SUCCESS",
"date": "Tue, 14 Sep 2021 15:21:13 GMT",
"url": "https://music.apple.com/us/artist/pearl-jam/467464/see-all?section=top-songs",
"httpCode": 200,
"result": {
"xpathElements": [
{
"xpath": "//div[@class=\"songs-list-row__song-name\"]",
"textNodes": [
"Black",
"Alive",
"Even Flow",
"Jeremy",
"Yellow Ledbetter",
"Better Man",
"Last Kiss",
"Daughter",
"Better Man",
"Just Breathe",
"Just Breathe",
"Elderly Woman Behind the Counter In a Small Town",
"Even Flow",
"Once",
"Release",
"Daughter",
"Sirens",
"Garden",
"Elderly Woman Behind the Counter In a Small Town",
"Jeremy",
"Why Go",
"Animal",
"Yellow Ledbetter",
"Porch",
"Oceans",
"Yellow Ledbetter",
"Given to Fly",
"Corduroy",
"Go",
"Rearviewmirror",
"Dissident",
"Who You Are",
"Dance Of The Clairvoyants",
"Last Kiss",
"Alive (2004 Remix)",
"Nothingman",
"Rearviewmirror",
"Superblood Wolfmoon",
"State of Love and Trust",
"World Wide Suicide",
"Corduroy",
"Dissident",
"Deep",
"Alive (2008 Brendan O'Brien Mix)",
"Black (2004 Remix)"
],
There’s a lot there, much of which is not relevant. However, we don’t need to worry about all of it. If you want to use Excel web scraping techniques, you can primarily focus on just one part of the field: “results.”
You’ll see a long list of song titles under this field. Those are the titles we care about. If we want to convert those titles into a spreadsheet format with other data, we need to know the exact arrays we care about. Specifically, these titles are stored in the “textNodes” array.
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, compatible with all automation frameworks.
Rayobyte’s Web Scraping API uses “textNodes” for the text entries that the program found based on the elements that matched the selector.
1. Converting the Data to Tables

Now that you understand the data you need to capture, you can start converting the data to tables. You can accomplish this in several ways:
Using online converters
The easiest solution by far is to use an online converter. There are many online programs that will convert JSON arrays into tables. These programs are great for one-off or occasional conversions. Some will let you upload entire JSON files, while others request you past the arrays you want to convert into CSV format. If you’re only performing occasional conversions, this is the simplest solution.
Coding JSON to CSV conversions
More complicated solutions involve building some code that will convert your JSON response into a CSV file for you. You can do this with languages like Python and Java. Let’s look at an example in Python.
First, you need to import JSON and CSV file formats into your Python program.
import csv
import json
This ensures that the program will be able to read and use these file types.
Next, you need to open the JSON file you want to use.
with open(‘file.path’) as scraper_data:
scraperinfo = json.load(scraper_data)
This bit of code loads the file into Python. Next, you want to open a CSV file to which you’ll write the data:
scraper_file = open(‘scraper_data.csv’, ‘w’)
This line opens a new CSV file called “scraper_data.csv” and gives Python permission to write to it.
Now, you need to create a CSV writer object. This object is what will actually put data into your CSV file.
csvwriter = csv.writer(scraper_file)
Finally, you can add data to the file and save it.
for info in scraperinfo:
csvwriter.writerow(info.values())
data_file.close()
This code is a bit longer because it all works together. The “for info in scraperinfo” line is a loop. The loop takes the next line, “csvwriter.writerow(info.values()),” and instructs “csvwriter” to write the values found in “info” to the CSV file.
Finally, “data_file.close()” ends the process. Congratulations! You’ve written a program that will turn your JSON response into a CSV file. All you need to do is save the specific arrays you care about to their own file and you’re ready to go. Here’s how it looks all in one place:
import csv import json with open(‘file.path’) as scraper_data: scraperinfo = json.load(scraper_data) scraper_file = open(‘scraper_data.csv’, ‘w’) csvwriter = csv.writer(scraper_file) for info in scraperinfo: csvwriter.writerow(info.values()) data_file.close()
2. Customize the Tables

You can do more than just convert the data into a generic table — you can also customize your tables to include header rows, which will make it much easier to transform the information you’ve collected through your web scraper with Google Sheets or Excel. There are two possible ways to accomplish this:
Generating manual header rows
First, you can add a header row manually. This is simple: right-click on the top row of data, then click “Add Entire Row.” A clean row will pop up above the rest of the data.
Here, you can input column names. You’ll need to manually type them in, but you’ll be able to edit them as you please. These column names will make it easier for you to sort your data and find the information you care about.
The manual method is fine if you only need to perform web scraping with Google Sheets occasionally. However, if you want to scrape data from a website to excel regularly, it’s worth automating this process.
Generating automatic header rows
If you want your program to automatically generate header rows, you’ll need to rework your code from what we did above. Remaining in Python, the simplest solution is to add a loop that puts a header to the top of the data and turns off to write the rest of the file. Here’s what that loop looks like:
count = 0 for info in scraperinfo: if count == 0: header = info.keys() csvwriter.writerow(header) count += 1
This loop finds the “keys” in the JSON file. In standard key-value arrays, this will put the key as the header and the values listed underneath it. It should result in a file that looks like the one above. The program as a whole will look like this:
import csv import json with open(‘file.path’) as scraper_data: scraperinfo = json.load(scraper_data) scraper_file = open(‘scraper_data.csv’, ‘w’) csvwriter = csv.writer(scraper_file) count = 0 for info in scraperinfo: if count == 0: header = info.keys() csvwriter.writerow(header) count += 1 csvwriter.writerow(info.values()) data_file.close()
Make Your Web Scraper Better Today

Once you’ve learned how to scrape data from a website into Google Sheets or Excel, you’re set for life. It’s a relatively simple process, especially if you use a service like Rayobyte’s Web Scraping API. The clean, easy-to-read arrays make it simple to generate Excel web scraping files. From there, you can perform any analysis you like.
Of course, it’s best to pair your web scraper with high-quality proxies. Top-notch proxies like Rayobyte’s residential proxies and ISP proxies help ensure that your results are never compromised. Your web scrapes will finish without running into inconvenient blocks. This lets you be more hands-off and trust your program to finish its automated data scraping from websites into Excel. You care about making your web scraper the best it can be — take the next step by adding Rayobyte proxies.
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, compatible with all automation frameworks.
The information contained within this article, including information posted by official staff, guest-submitted material, message board postings, or other third-party material is presented solely for the purposes of education and furtherance of the knowledge of the reader. All trademarks used in this publication are hereby acknowledged as the property of their respective owners.



