Tips For Web Scraping Without Getting Blacklisted
Data is the engine that helps online businesses run. And the way a lot of business owners get that data is by web scraping. Done ethically, web scraping can be a valuable source of information without being an inconvenience to website owners.
If you’re considering web scraping, you might know that hitting a website with too many data requests can make you seem like a cyberattacker — and result in you being blocked. How can you effectively scrape data without getting blocked or blacklisted?
Fast, Effective, Efficient
Get the API that can meet your web scraping needs.

Here we’ll explore some ways to get around website blocks so you can get the data you need without causing trouble for website administrators.
Common Methods Used to Block Web Scraping

Site administrators have developed a variety of ways to block web scraping. CAPTCHAs, HTTP request header checks, and javascript checks are just a few of the methods websites use to protect their data. The first step in knowing how to crawl a website without getting blocked is to be aware of the potential blocks you may encounter.
We’ll go over some common ones as a primer so you know what to look out for before we talk about how to get around them.
Robots.txt Files
The first line of defense is often the robots.txt file, which is short for “robots exclusive standard” or “robots exclusion protocol.” It’s a file embedded into the code of a web page that specifies where web crawlers — the programs that automatically comb through web pages — are allowed to go.
Most mainstream web crawlers like the ones used by Google and Bing will respect the instructions within a site’s robots.txt file. It’s possible to build a bot that can go around it, but it’s not recommended — hammering a site with requests will make the admin think it’s under attack.
IP Blocking/Tracking
This is among the most common anti-scraping methods that sites use. The site will simply keep track of the internet protocol (IP) address of each request it gets sent for a certain page. If a large number of requests come in from a single address, it’s assumed to be a bot.
Most sites will set a limit to the number of requests a single IP can make before getting blocked — usually somewhere around 10 per minute. Exceed that, and your IP address will be barred from accessing that site.
AJAX
Short for Asynchronous JavaScript and XML, this method uses JavaScript to retrieve data from a page without requiring it to refresh. Because a lot of popular web scraping bots can’t render JavaScript, this makes it impossible for them to read the site and get the data from it.
Since sites using AJAX send data after the HTML has loaded, any bot sending a request will get an HTML page with no data on it unless it can execute and render JavaScript.
Browser Fingerprinting
Browser fingerprinting uses information from the browser you’re using to identify you and can work even if you change IP addresses using proxies. It’s a common method of tracking, along with cookies and IP logging.
There are two types of fingerprinting you’ll encounter: static and dynamic.
- Static fingerprinting: This uses data from request headers to identify your browser.
- Dynamic fingerprinting: This uses JavaScript to pull information like what fonts, plugin, color depth, and screen size you’re using to compare it to previous requests.
CAPTCHAs
We’ve all seen these before, but you might not know what the acronym actually means. CAPTCHA stands for: completely automated public Turing test to tell computers and humans apart.
Users are required to recognize and type out some text or click on a set of images to prove they’re human.
These tests usually appear as a precautionary measure, or when a site starts getting too many requests from a single IP address. Once they appear, you’re pretty much done scraping that page as they’re very difficult to solve by automated means.
Honeypot Traps
This is when code is written into the page to make it enticing to web crawlers but unavailable to regular human users. Once a crawler accesses the page, the administrator knows it’s a bot and automatically blocks it.
This is usually accomplished by writing code into the CSS style sheet of the site that makes things invisible to users. Attributes like visibility:hidden or display:none will hide elements from human visitors so only bots can see them.
How to Prevent Getting Blacklisted While Scraping

They’re difficult to get around, but it is possible to get around anti-scraping methods. It all comes down to knowing what method the site is using to detect traffic. Using the following tips can help you be nearly undetectable, letting you crawl a website without getting blocked in many cases.
Rotate Your IP Addresses
Since one of the most common ways of tracking web scrapers is via their IP address, you might be wondering how to get around an IP ban. One of the best ways to web scrape without getting blocked is to rotate them out. Having a number of IP addresses ready to use helps any requests you send to the page appear to be coming from different users.
Proxies make this relatively simple. Proxies act as an intermediary between your device and the internet and send the request for information to the server on your behalf. Once they get the information, they send it back to your actual machine.
This is not recommended for hammer pages with requests using multiple IPs, however. It’s unethical and can result in you getting blocked — even if you’re using multiple IPs. Any proxies you use should always be ethically sourced from a trusted provider.
Ethical proxies like those with Rayobyte are a great tool if you’re wondering how to avoid an IP ban.
Set Different Request Headers
To make a scraping bot appear to be an actual browser, you can build in request headers. If you have no idea where to get them, don’t worry — sites like this one will tell you which ones your browser is using.
Just navigate to the page and copy the relevant code from the “headers” section. When you navigate there with the latest version of Chrome, for example, you get this:
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9",
"Dnt": "1",
"Host": "httpbin.org",
"Referer": "https://www.scraperapi.com/",
"Sec-Ch-Ua": "\"Chromium\";v=\"92\", \" Not A;Brand\";v=\"99\", \"Google Chrome\";v=\"92\"",
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "cross-site",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-610ad82f-1d504494665938b864358b76"
Paired with rotating IP addresses, this can cloak your requests pretty effectively when web scraping.
Set A Real User Agent
User agents are a header in the code that tells a website’s server what browser you’re using. Some sites will use the user agent header to block a request if it doesn’t come from a major browser like Chrome or Safari.
Neglect to add a user agent, and any web scraping bot you use will get detected and blocked quickly. Set a common user agent for your crawler instead. You can find a list of them here. Once you add the user agent, check periodically to make sure it’s up to date so it doesn’t get blocked.
Another common header you can set to make your crawler appear real is a referrer. It’s a header that lets a website know which site you’re coming from. Setting your referrer to “Referer”: “https://www.google.com/” is usually a safe bet since most sites want to let Google access them.
Vary Request Intervals
If your web scraping bot sends one request every second for hours at a time, it’s going to be pretty obvious it’s a robot. No human would sit there refreshing a web page at exact one-second intervals.
To avoid getting recognized and blocked, time your requests to the website at random intervals so they appear to be coming from actual people. Randomized delays of anywhere from 2-10 seconds should be fine.
Do not overload a page with requests — this cannot be stressed enough. Be polite. Check the site’s robots.txt file — there will often be a line with the text “crawl-delay” that tells you exactly how long a web scraper should wait between requests. If that’s there, abide by it.
Check For Honeypot Traps
Some webmasters will set links to be invisible to normal users and therefore know automatically when a bot crawls them. Once that happens, you’ll be easily detected and blocked. To avoid that, check for properties like “display: none” or “visibility: hidden” in the page’s CSS style sheet.
Another way honeypot traps are set up is to make the links the same color as the page background. That color is often white, so it’s useful to check for the hex value of that color in the CSS properties. It could look like “color: #fff;” or “color: #ffffff.”
Getting Around Web Blocks To Get the Data

Now that you know some common methods used to block web scraping, you can get around them to get the data you need. This should always be done ethically and with respect to the site owner — a large part of the reason these countermeasures get used is unethical and inconsiderate web scraping.
Fast, Effective, Efficient
Get the API that can meet your web scraping needs.
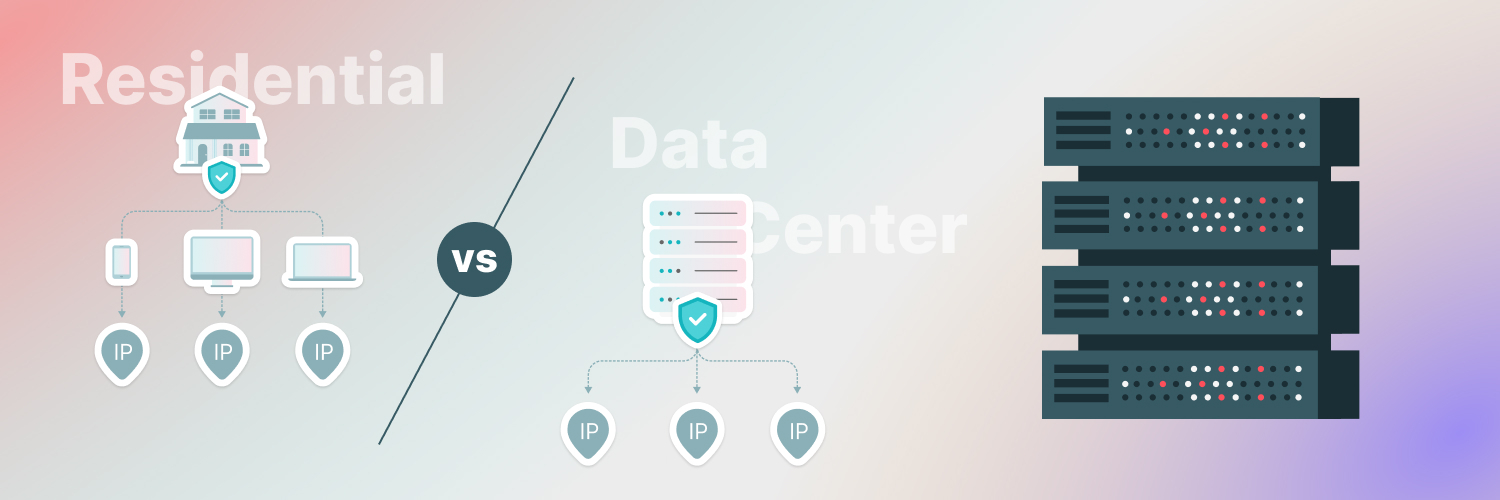
Proxies are an integral part of masking your requests when scraping data. Rayobyte offers both data center and residential rotating proxies, and they’re always ethically sourced. While both proxies are great for data scraping, because residential rotating proxies come from ISPs, they’re the most reliable option — and they’re less detectable. Check out Rayobyte’s residential rotating proxies to help effectively scrap data for your business.
If you’re hungry for more tips on proxies and web scraping, check out the Rayobyte blog.
The information contained within this article, including information posted by official staff, guest-submitted material, message board postings, or other third-party material is presented solely for the purposes of education and furtherance of the knowledge of the reader. All trademarks used in this publication are hereby acknowledged as the property of their respective owners.