How IP Reputation Actually Works (And Why It Matters For Scraping)
If you’ve been scraping for any length of time, you’ve probably heard someone say, “That IP got burned,” or “We need a cleaner pool.” What they’re really talking about is IP reputation.
IP reputation sounds mysterious at first, almost like there’s some secret blacklist floating around the internet judging your infrastructure. In reality, it’s a lot more practical than that. IP reputation is simply the cumulative trust score that websites and services assign to an IP address based on its past behavior.
And when you’re collecting data at scale, that trust score matters a lot.
If your IPs are trusted, requests flow smoothly, pages load consistently, and your pipeline behaves predictably. If they aren’t, you’ll start seeing subtle friction that eventually turns into outright failures. Response times increase, success rates dip, retries pile up, and costs creep upward. Everything feels harder than it should.
Understanding how IP reputation actually works gives you a massive advantage. It helps you design scraping systems that are stable rather than fragile and scalable rather than constantly patched together.
Let’s take a look at what’s really happening under the hood.
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, compatible with all automation frameworks.

What IP Reputation Really Means
At its core, IP reputation is about behavior history.
Every IP address that sends traffic across the internet leaves behind patterns. Websites, content delivery networks, and security systems observe how that IP behaves over time. They notice how frequently it makes requests, what types of pages it visits, whether it generates errors, and whether its activity resembles normal user behavior.
Those observations feed into internal scoring systems, and the result is a dynamic trust profile attached to that IP.
This doesn’t mean there’s a single global “reputation score” shared across the entire internet. Instead, each major platform maintains its own view. An IP might be perfectly fine on one site and heavily restricted on another. Reputation is contextual.
For scraping teams, that context is everything.
How Websites Evaluate IP Behavior
Websites use a mix of signals to assess IP reputation. None of them are especially exotic on their own, but together they paint a clear picture.
First, there’s request frequency. If an IP makes an unusually high number of requests in a short time frame, that stands out. Even if the data being requested is public, repetition at scale triggers protective systems designed to preserve infrastructure stability.
Second, there’s consistency of behavior. Human traffic tends to vary. People browse different pages, pause between clicks, and move unpredictably. Highly uniform traffic patterns look different.
Third, there’s error rate. If an IP consistently generates failed requests, timeouts, or malformed interactions, that contributes to a lower trust profile.
Over time, these signals accumulate. A stable, well-managed IP builds a strong reputation. An IP associated with aggressive or erratic patterns builds a weaker one.
Why Reputation Feels Invisible Until It Breaks
One of the most frustrating aspects of IP reputation is that you rarely notice it when it’s healthy. Everything just works.
The first signs of trouble tend to be subtle; response times increase slightly, a small percentage of requests start failing, certain endpoints behave inconsistently. It’s easy to assume it’s a temporary glitch.
As reputation declines further, the friction becomes more obvious, or requests may be delayed deliberately. Some pages may return incomplete content. Eventually, outright blocking can occur.
Because reputation degrades gradually, teams often misdiagnose the problem. They tweak parsers, adjust timeouts, or increase retries without realizing the root cause is trust erosion at the IP level.
Understanding that reputation exists, and that it evolves over time, helps you spot these patterns earlier.
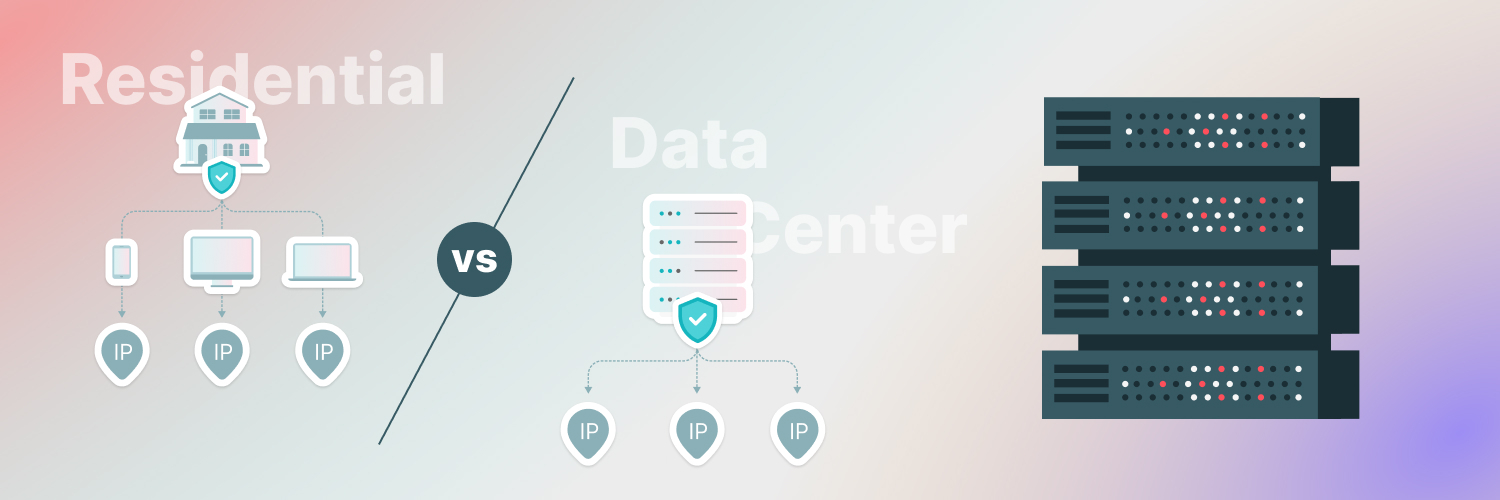
Datacenter vs Residential IP Reputation Dynamics
IP reputation behaves differently depending on the type of IP you’re using.
Datacenter IPs are easier for websites to identify as non-consumer traffic. That doesn’t automatically mean they’re “bad,” but it does mean their reputation profile is evaluated through a different lens. High request volume from a datacenter IP will be scrutinized more closely because it’s clearly infrastructure-driven.
Residential IPs originate from consumer networks, which naturally resemble everyday browsing. This can make them appear more trustworthy in certain contexts, especially when collecting data that’s closely tied to consumer experiences.
However, reputation still applies. A residential IP that generates highly repetitive, high-volume traffic can also see its trust degrade over time.
The takeaway is that reputation is behavioral, not purely structural. IP type influences perception, but behavior ultimately determines outcomes.
Protect Your IP Reputation at Scale
Build stable scraping pipelines with clean, transparent proxy infrastructure.
How IP Pools and Rotation Influence Reputation
IP rotation plays a central role in reputation management.
If all your scraping traffic flows through a small number of IPs, those IPs accumulate behavioral signals quickly. Even moderate volume can start to look excessive when concentrated.
When traffic is distributed across a larger pool, each individual IP carries less weight. This reduces the likelihood of any single address developing a negative profile.
That said, rotation alone is not a cure-all. If overall traffic patterns are aggressive or poorly distributed, simply cycling through IPs can spread the problem rather than solve it.
Healthy reputation management combines intelligent rotation with thoughtful rate limiting and monitoring.
Geographic Consistency and Trust Signals
Geolocation adds another layer to IP reputation.
Websites often expect traffic from certain regions to behave in predictable ways. If an IP appears to originate from one country but exhibits patterns inconsistent with that region, trust can decline.
Accurate geolocation recognition matters here. IPs that map cleanly to established geolocation databases tend to generate fewer inconsistencies. When region data is misaligned, websites may respond conservatively.
For scraping teams collecting region-specific data, maintaining geographic consistency strengthens reputation over time.
Common Behaviors that Damage IP Reputation
While reputation systems vary across platforms, certain behaviors consistently erode trust.
High bursts of traffic in short windows are one. Repeatedly hitting the same endpoint at perfectly regular intervals is another, and excessive retries that double or triple request volume can also contribute.
Poor error handling makes things worse. If your system keeps hammering an endpoint that’s already slowing down, reputation declines faster.
It’s rarely one dramatic event that causes problems. It’s accumulation. Small inefficiencies compound over time until an IP’s profile crosses a threshold.
Why “Burned” IPs are Usually a Symptom, Not the Problem
When teams describe IPs as burned, what they’re really describing is accumulated behavioral damage.
Swapping out the IP might restore short-term performance, but if the underlying traffic patterns remain unchanged, the new IP will follow the same path.
Reputation issues often reveal architectural problems. Overly aggressive concurrency, poorly tuned retry logic, or insufficient distribution across pools all contribute.
Addressing reputation sustainably means improving system design, not just rotating inventory.
Monitoring Reputation Before It Becomes a Crisis
Reputation management is easier when you track the right signals.
Instead of focusing solely on request volume, mature teams monitor success rate trends, latency percentiles, retry ratios, and region-specific consistency. Sudden shifts in these metrics often indicate early-stage reputation degradation.
By responding early, you can adjust traffic patterns before sites escalate their protective measures.
Good monitoring turns reputation from a mystery into a manageable variable.
How to Build Scraping Systems That Protect Reputation
Responsible scraping practices naturally protect IP reputation.
They distribute traffic across appropriately sized pools, use intelligent rate limiting rather than pushing for maximum speed at all times, and monitor error patterns and adapt rather than retrying blindly.
Treat IP reputation as a long-term asset rather than a disposable resource. The more predictable and stable your traffic patterns are, the more sustainable your data collection becomes.
Reputation management is all about maintaining operational stability.
How Rayobyte Approaches IP Reputation
At Rayobyte, we tend to think about IP reputation as part of the broader infrastructure design, not as a quick fix issue.
Our proxy networks are built to support intelligent traffic distribution, accurate geolocation, and stable rotation. We work with customers who care about long-term performance rather than short-term bursts.
We’re transparent about how our IPs are sourced and how our networks behave, and help teams tune rotation settings, concurrency levels, and monitoring systems so their scraping pipelines remain predictable over time.
When customers understand how reputation works, they make better architectural decisions. When infrastructure is aligned with responsible scraping practices, reputation tends to take care of itself.
IP reputation isn’t magic, and it isn’t arbitrary. It’s the natural result of how traffic behaves over time.
When you understand that, scraping becomes less about reacting to sudden failures and more about designing systems that age gracefully.
Trusted IPs lead to smoother pipelines. Smoother pipelines lead to cleaner data. Cleaner data leads to better decisions.
Reputation is invisible when it’s healthy, which is exactly how you want it.
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, compatible with all automation frameworks.