Web Scraping Without Getting Blocked With Python
Web scraping enables you to capture incredible information you can use for a variety of activities. However, to do that, you need to be able to get around the anti-bot technology that is out there. Web scraping without getting blocked with Python is possible if you know what to do to avoid the most common problems.
In this guide, we will teach you how to crawl a website in Python without getting blocked and provide you with the hands-on tools and strategies you need to overcome various obstacles.
The Easiest Way To Get Started
Try our Web Scraping API for hassle-free results!

Web Scraping Without Getting Blocked: Know Why It Happens

Web scraping is the process of extracting data from a website using a web browser or HTTP protocol. This method can be done manually, but automating it with the help of a web crawler tends to be essential. The problem is web scraping isn’t simplistic because not every website wants to use its resources to send you information.
Web scraping is legal, unless you are accessing non-public data (and we do not encourage you to do this). So, why are you blocked when trying to engage in legal web scraping actions?
- The website owner wants to protect their data.
- The website owner wants only people who can add value to the website to use that information.
- Web scraping activities can overload servers and cause delays for others.
- Companies do not want you to have access to intellectual property, as that can lead to theft.
- The website’s terms and service are meant to protect specific information.
- They don’t want you or anyone else to have a competitive advantage.
The list can go on. Once you know the reasons, you can create a strategy to overcome it. Here is how to crawl a website without getting blocked in Python.
Our Solution for Web Scraping Without Being Blocked

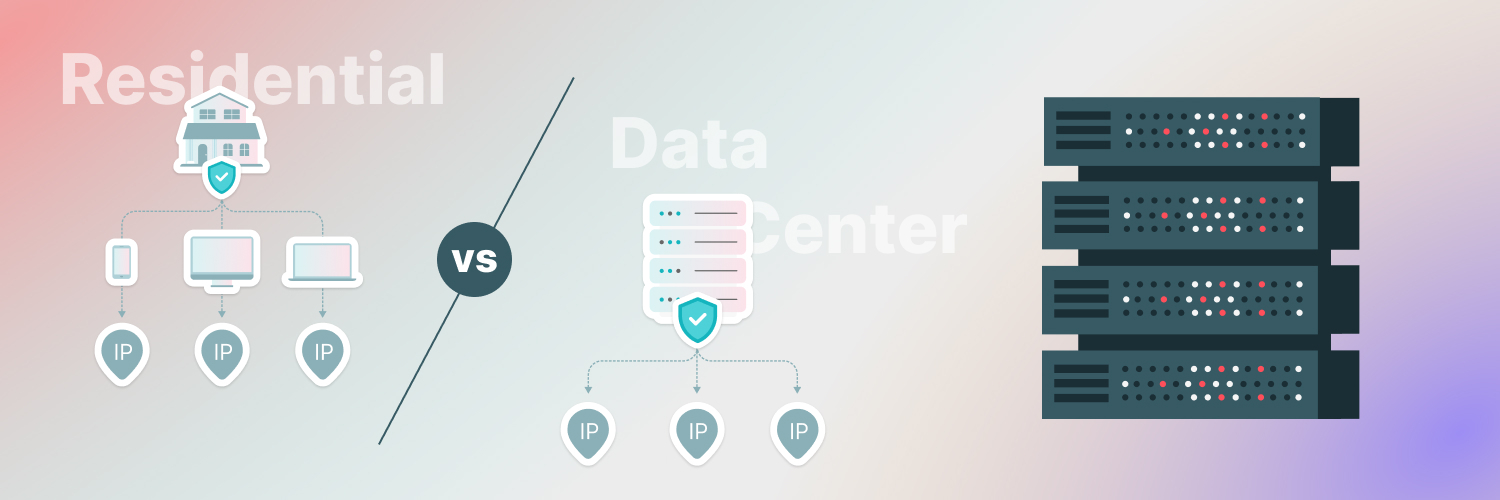
A number of strategies exist to help you get around the common blocks for web scraping. At Rayobyte, we offer a variety of insights to help you navigate all of the obstacles out there. One of the best ways to overcome these limitations is by using rotating proxies, a process that changes your IP address on a frequent basis. Using libraries like ProxyManager or integrating services like Rayobyte proxies, it is possible to mask your IP address immediately. That means there is no reason for websites to suspect you for the activities you are engaging in.
We encourage you to implement user-agent rotation services and header management using Python’s libraries, including Requests and Scrapy.
If you are not familiar with these tools, take a minute to start here:
- The Ultimate Guide to Using Python Requests for Web Scraping
- Web Scraping with Scrapy – A Complete Tutorial
These tools help you to minimize the risks of being detected for web scraping. You can employ delays, randomize requests, and even overcome the challenges of human verification using these tools, including tools like anti-human verification APIs. Each one of the following methods is an option for moving beyond the anti-bot technology. Keep in mind that we only encourage you to engage in ethical and efficient methods for web scraping.
Scraping Without Getting Blocked: Use These Methods for Success

As noted, there are numerous ways to engage in web scraping without getting blocked in Python. The following are options that may work for a variety of your challenges.
Rotating proxies: A rotating IP address can solve just about all of the problems you may be having with web scraping. A rotating proxy is one that will supply a different IP address from a set of stored options in a proxy pool. From the destination website’s view, it looks like a different person is visiting the site every time. This can help you avoid getting detected.
To do this, you need to write a web scraping script that will allow you to use any IP address within the pool and let you make a request using the same IP. That is where the process can be challenging.
We encourage you to check out the services we offer at Rayobyte. This can make it far easier and more efficient for you to get started. Once you set up a proxy service with us, you will then be able to capture your proxy IP address information.
Now, let’s say you are going to use our rotating proxies. You can get a list of them manually or automate them using a scraper. Here is what your code could look like to do this:
import requests
# use to parse html text
from lxml.html import fromstring
from itertools import cycle
import traceback
def to_get_proxies():
# website to get free proxies
url = 'https://rayobyte.net/'
response = requests.get(url)
parser = fromstring(response.text)
# using a set to avoid duplicate IP entries.
proxies = set()
for i in parser.xpath('//tbody/tr')[:10]:
# to check if the corresponding IP is of type HTTPS
if i.xpath('.//td[7][contains(text(),"yes")]'):
# Grabbing IP and corresponding PORT
proxy = ":".join([i.xpath('.//td[1]/text()')[0],
i.xpath('.//td[2]/text()')[0]])
proxies.add(proxy)
return proxies
Now, this code is incomplete – you need to update it with the Rayobyte address when you reach that point. In other words, you will need to sign up for a service and be given access to a list of scraping IP address options.
The code here, though, offers some insight into how your final product should look. This will give you a long list of IP addresses that will work as a way to rotate from one to the next. Remember, you could do this manually, but that process will take a significant amount of time and effort and can make web scraping less effective.
Let’s assume you have a list of the available IP proxies to use for rotating. Our goal is to ensure that every website request is sent using a different IP address. With the list of IP addresses available to you, apply a round-robin method, which will circulate the IP addresses so that they consistently change.
Here is what this type of code will look like – though you will need to update this to match your specific needs:
proxies = to_get_proxies()
# to rotate through the list of IPs
proxyPool = cycle(proxies)
# insert the url of the website you want to scrape.
url = ''
for i in range(1, 11):
# Get a proxy from the pool
proxy = next(proxyPool)
print("Request #%d" % i)
try:
response = requests.get(url, proxies={"http": proxy, "https": proxy})
print(response.json())
except:
# One has to try the entire process as most
# free proxies will get connection errors
# We will just skip retries.
print("Skipping. Connection error")
You can update this to include all of your specific limitations and goals. What you will quickly find is that this method works very well.
TIP: Use Paid Proxies

We encourage you to use proxies for this task because they can work very well to minimize the stresses you face during web scraping. However, paid rotating proxies make a huge difference in your success. We strongly encourage you not to simply use free proxies for important projects.
Web Scraping API: Another option you have for web scraping without getting blocked is using a web scraping API. Take a look at how our web scraping API could help you.
If you are new to this process, start out by checking out our guide: Proxy API (What Is This Thing, and How Does It Work?). If you read that guide, we don’t need to provide you with a full breakdown of how to use a proxy API.
Data Extraction Made Easy!
What this can do for you, though, is offer the commonly used anti-bot blocking technologies. It will automatically bypass all of the anti-bot measures the website is implementing.
Check out the Web Scraping API at Rayobyte to get started.
Headless Browsers: Another strategy to scrape without getting blocked is to use a headless browser. These tools are more complex and usually meant for more advanced users, but they are so important that we need to include them here.
If you want to avoid being blocked during web scraping, it is critical to interact with the website just like any other user would. To do that, consider the value of a headless web browser. This process works without the need for a graphical user interface, mimicking more authentic and less bot-like activities.
There is a variety of tools available that you can use for this. We recommend taking a closer look at our guides on these tools to help you determine which headless browser option may be best for you:
- Ultimate Guide to Selenium Web Scraping and Proxies
- Playwright Web Scraping with Python (Complete Guide)
- Puppeteer Tutorial (Master Puppeteer Web Scraping)
The use of headless browsers is beneficial for scraping websites that use JavaScript. They will execute JavaScript for you, allowing you to circumvent anti-bot checks.
Utilize Real Request Headers

Another strategy to help you avoid web scraping without getting blocked with Python includes the use of real request headers. These headers reveal metadata information about the request. This is one of the various components of anti-bots checks to stop web scraping and other tools like it.
In other words, if you have an actual request header from a real browser, you are less likely to be blocked as a result. The problem is that most of the default request headers that tools for web scraping use do not actually resemble what an authentic browser will. And because of that, they are detected by the technology.
Compare these bites of code.
The first one is what you can commonly see with a web scraping tool:
{
"headers": {
"Accept": [
"*/*"
],
"Accept-Encoding": [
"gzip, deflate, br, zstd"
],
"Connection": [
"keep-alive"
],
"Host": [
"httpbin.io"
],
"User-Agent": [
"python-requests/2.32.3"
]
}
}
What you should notice here is that there is a lot of “missing” or generic information within this code. That gives the website a signal that you may be using a bot instead of being an authentic website visitor.
By comparison, look at this real request code. You can see a significant difference in the functionality immediately.
{
"headers": {
"Accept": [
"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7"
],
"Accept-Encoding": [
"gzip, deflate, br, zstd"
],
"Accept-Language": [
"en-US,en;q=0.9"
],
"Connection": [
"keep-alive"
],
"Host": [
"httpbin.io"
],
"Sec-Ch-Ua": [
"\"Not/A)Brand\";v=\"8\", \"Chromium\";v=\"126\", \"Google Chrome\";v=\"126\""
],
"Sec-Ch-Ua-Mobile": [
"?0"
],
"Sec-Ch-Ua-Platform": [
"\"Windows\""
],
"Sec-Fetch-Dest": [
"document"
],
"Sec-Fetch-Mode": [
"navigate"
],
"Sec-Fetch-Site": [
"none"
],
"Sec-Fetch-User": [
"?1"
],
"Upgrade-Insecure-Requests": [
"1"
],
"User-Agent": [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
]
}
}
Scrapy: Many people find Scrapy to be the best tool. It is a fast and powerful tool and an open-source powerhouse. This collaborative framework will help you extract the data you need in a simple but effective manner.
There are various benefits to using Scrapy as a component of your web scraping. It can:
- Provide faster crawling and scraping, getting more of what you need to be done sooner
- It can handle large-scale data acquisition, often doing so without creating inefficiencies
- Create highly customizable processes
- Use memory-efficient processes
- Smooth out the experience and get more reliable results.
Need More Solutions? We Can Help You

At Rayobyte, we offer a huge range of methods that can help you to handle any type of difficult task. If you are looking to scrape without getting blocked in Python, start with our services. Learn more about how our team can guide you.
Rayobyte provides you with real proxies and ensures you gain access to real data. Contact us now to learn more about the variety of options we can help you with to make sure you are not blocked.
The information contained within this article, including information posted by official staff, guest-submitted material, message board postings, or other third-party material is presented solely for the purposes of education and furtherance of the knowledge of the reader. All trademarks used in this publication are hereby acknowledged as the property of their respective owners.