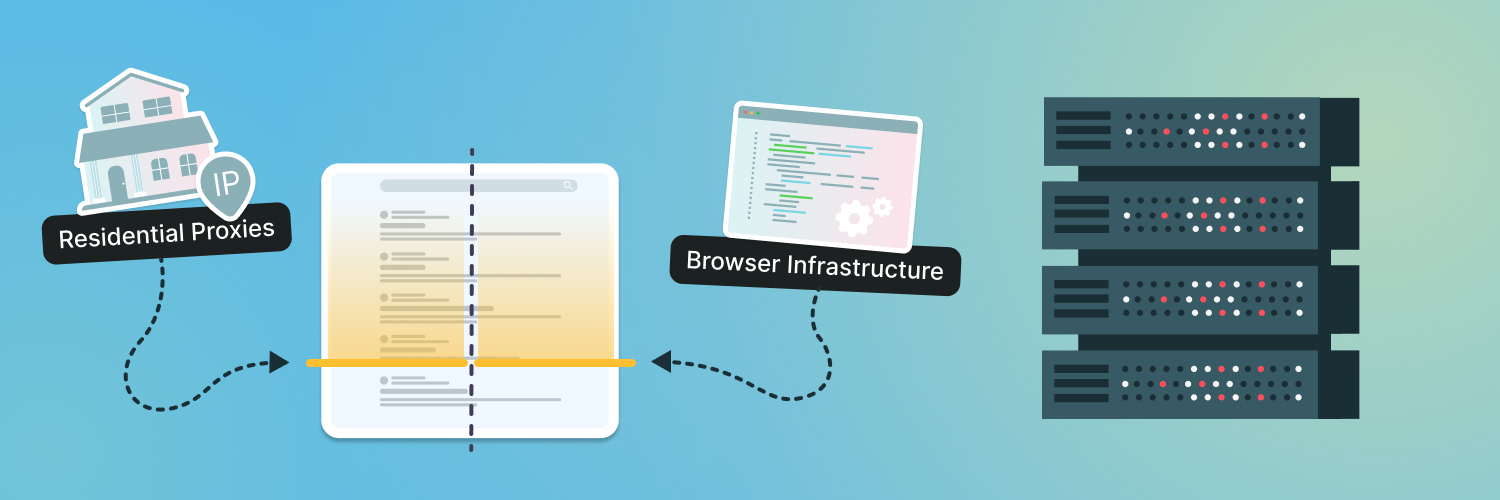
How a Web Scraping Proxy Enhances Your Business Strategy
Ask any expert what is a must-have for website scraping, and the answer will most likely be proxies. Without them, you can’t expect the web scraper to do much because, one way or another, it will end up failing.
Most web scraping applications undertake the enormous task of scraping through thousands and even hundreds of thousands of web pages. Regardless of the use case, web scraping using a proxy delivers more reliable results.
To understand all of that and how to use web scraping proxy, you need to understand web scraping, proxies, and how they work together in detail.
Even with the use of proxies, small mistakes can cause big trouble. Therefore, it’s imperative to use good proxies from a reliable provider.
This guide will take you through everything you need to know about a web scraping proxy, in general, as well as website proxies for the best proxy scraper.
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, compatible with all automation frameworks.

What Is Web Scraping?

Before we talk about proxies, let’s take a moment to discuss web scraping.
Web scraping is the process of extracting and collecting data from websites. A web scraper is a program or tool that extracts and organizes the data from a webpage in a useful format, usually a local file on a computer or a spreadsheet with records.
Think of it as a simple copy and paste operation. However, web scraping is going on in the background as the web scraper parses through the HTML code of the web page.
While you can make your own web scraper from scratch using any common programming languages like C#, Java, or Python, today, many web scraping tools are available that make the process even easier.
These tools automate the entire process, which essentially allows them to scrape through many web pages at lightning-fast speed. These are often referred to as bots or Rayobyte’s Web Scraping APIs.
But keep in mind, just having a web scraper is not enough to successfully go through websites without ever getting banned or blacklisted.
Also, it’s essential to understand the difference between web scraping and web crawling. People often confuse the two and use the terms interchangeably, which is not entirely correct.
Both processes are linked, though. A web crawler’s job is to find websites (URLs), whereas a web scraper’s job is to extract data. Often, a web scraper relies on a web crawler for the web page addresses it will extract data from. So these are often used in conjunction, but at the core, are different processes.
What Is a Web Scraping Proxy?

A web scraping proxy simply refers to a proxy server used for web scraping purposes. A proxy is a server that allows you to pass your request through it and use its IP address.
To understand this definition, you should also know what an IP address is. Every device that connects to a network, like the Internet, has a unique numeric address that represents it. This allows the other devices in the network to identify it.
192.0.2.1 is an example of an IP address.
What a proxy or proxy server essentially does is change your IP address. When you send a request, or when you run the scraper, it routes through the third-party server. The server on the other end, which is hosting the website, sees their IP address, not yours.
The HTTP request will go directly to the website without a proxy server between you and the website the scraper wants to scrape. The server will use a proxy and become an intermediary between the scraper and where the request is going.
When talking about a web scraping proxy, it’s important to mention that while the tech industry is moving towards IPv6, proxy providers still use IPv4, which is not a big issue. The main advantage of IPv6 is that there are significantly more IP addresses available in the format. This is important in the world of Internet-of-Things, where people are connecting more and more devices to the Internet. Every device connected to the Internet, whether a smart TV, fridge, camera, phone, etc., needs an IP address.
Now, you’re probably wondering where you find such servers? Well, proxy servers are essentially servers at the end of the day, and many companies and server farms provide proxy servers.
Why Use a Reliable Proxy for Web Scraping?

Web scraping can be far from easy. This is where proxy web scraping comes in!
Here’s how using a reliable proxy for web scraping benefits you when scraping the web:
Hide your IP address
The main reason enterprises use a web scraping proxy is because it allows them to hide their source machine’s IP address. Your unique IP address can quickly get blocked from accessing a website or similar sites; a proxy helps hide it and prevents it from getting blacklisted.
This way, the target website doesn’t get to know your real IP address, so even if it blocks an IP, that doesn’t affect your source machine, where the web scraper resides and sends requests from.
A web scraper sending requests through a proxy server can use multiple IP addresses, further reducing the chances of getting blocked.
Exceeding the rate limits
The websites that don’t mind web scrapers hanging around often limit the number of requests they can send in a given duration. If the target website realizes that limit is crossed, it can ban the IP address sending the requests.
Now, this can be a problem when you’re targeting a website with hundreds or even thousands of web pages. Your scraper may easily exceed that rate limit and get your IP blocked.
Proxies solve this problem by using multiple IP addresses while staying within the request rate limit for each IP address used. Proxy servers distribute the requests over different IP addresses.
Request from a specific location
Another benefit of using a premium proxy for web scraping is that you can send requests from a specific geographical location different from yours. This comes in handy for scraping websites that have different content for different locations.
Similarly, some websites use geo-blocking to prevent users from accessing the website from a particular geographical area or region.
By using proxy servers with IP addresses from other geographical locations, a scraper can bypass these barriers. It can help the scraper access the different location-based versions of the same website.
This is usually the case with many e-commerce websites that automatically display the website designed for the region the request is coming from. While you can often change the location of the website manually, a web scraper may not be able to do that, which is why proxies are a better option.
Types of Proxies for Web Scrapers

Now that you understand what a web scraping proxy server is and its use in web scraping, we can discuss different types of proxies.
There are essentially three types of proxies based on the IP addresses:
Residential IPs
Residential IPs are based on residential addresses, typically assigned by an Internet service provider (ISP). It’s a real IP address with a specific physical location, which can be anywhere in the world.
Such IPs are less likely to be blocked by a website server because they appear genuine, making it easier for a scraper to do its job and not get blocked.
These resident IPs also make it easier to visit a website’s specific location-based version to extract data. Since these can be resident anywhere, the scraper can bypass any geographical restrictions relatively easily.
The downside, however, is that these IPs are the most expensive. Nevertheless, this type is arguably the most reliable proxy for web scraping.
Data center IPs
These are the ones most web scrapers rely on. These IP addresses originate from data centers with servers, hence the name. As these IPs don’t have any link with an ISP, these don’t have a specific physical address like residential IPs.
These are the cheapest option of the three, which is why they remain popular for use with web scrapers.
Like residential IPs, these can also be from different geographical locations with servers present in various cities across the globe.
Data center IPs are cheap because they can be used more efficiently, like cloud servers. In other words, different scrapers can use them when available and as needed.
Mobile IPs
As the name suggests, these IPs are mobile devices provided through the network carriers. These serve the same benefit as residential IPs, reducing the chances of getting blocked and giving access to geo-specific content of certain websites.
It also means that through these IPs, the scraper will be accessing and scraping the mobile version of the website, which, in most cases, isn’t that different from the desktop version.
Much like residential IPs, mobile IPs are also pretty expensive.
Categories of Proxies: Public, Shared, and Dedicated

Aside from the three types of web scraping proxies, you also have to decide on the category. A proxy server may be public, shared, or dedicated.
- Public Proxies: These proxies are also called open proxies and are open to the public. This means anyone can access this proxy server, which is in itself a big red flag. Not only are these proxies very low-quality, but they often also have viruses and malware. This can be a risk for the machine hosting the web scraper, as requests made through public proxy leave it vulnerable. Even if you decide to go with a public proxy, it’s imperative to have proper security checks in place.
- Shared Proxies: In shared proxies, you’ll be sharing the IP address and resources with other clients. While this is economical, there’s a small risk of being blocked because of another client using the same IP address as you. Nevertheless, depending on the scale of web scraping, shared proxies may be a viable solution.
- Dedicated Proxies: Dedicated IPs serve as the premium proxy for web scraping, as the IP addresses and resources are only for your use. This, obviously, comes at a price, but it can be a good option for those scrapers that deal with very large volumes and have a generous budget.
Proxy Pools
Using a single web scraping proxy scraper is a recipe for failure. Relying on just one proxy server can significantly lower the ability of the web scraper to extract data from a website. In most cases, companies need to scrape through many web pages at a time.
For this reason, web scraping proxy pools are built and used to send multiple requests. This allows the web scraper to simultaneously send numerous requests to target servers and distribute those requests among several proxies.
Regardless of the type of IP you’re using, you need to create a web scraping proxy pool per your scraping performance and load needs.
Most proxy server providers provide proxy pools only, so you can pre-determine how many you’ll need in your pool.
How Many Proxies Do You Need?

There are many things you need to keep in mind when it comes to building a web scraping proxy pool. These considerations will help you determine the exact number of proxies you need in your proxy pool.
- Number of Requests: You need to determine the rate of requests, i.e., the number of requests you will send to the target website server in a particular duration. For instance, your target is 500 requests per 10 minutes. Generally, the higher this rate is, the larger the web scraping proxy pool should be.
- Size of Website: You should also consider the size of the website you’re targeting for scraping. If it’s one of those big ones with hundreds of pages, or it has stringent protocols in place for blocking scrapers, you’re going to need a bigger pool of proxies.
- Quality of IPs: Yes, the quality of IPs matters because a low-quality IP risks getting detected and blocked. The quality depends on the type of IP you’re using. Residential IPs are, of course, the top in terms of quality. Similarly, dedicated IPs are also much better than shared or public IPs.
Calculating the number of proxies
While you need to consider these factors, determining the right number of web scraping proxy servers is challenging. Most enterprises or SMEs using web scraping make the mistake of purchasing too big or too small of a proxy pool.
If you’re confused about the number of requests, here’s an example to help you determine the correct number.
Generally speaking, a human user would usually send not more than ten requests per minute over a certain period. Of course, it also depends on the content of the website and how it’s presented.
Even if the user opens multiple tabs on the same website within a matter of seconds, the requests won’t exceed, say, 300 an hour (five per minute) because they won’t be viewing all the tabs at the same time. There would be a pause between requests.
So keeping this scenario as a guideline, a request rate of 500 requests per hour or more would look suspicious for any website. So you should limit the requests to 500 per hour from a single proxy IP website.
This is just an example to help you determine a ballpark number. The problem is that some websites have even lower limits, which can hamper your scraping efforts. It comes down to the kind of websites you’re trying to scrape.
If your target websites are quite diverse, with some big ones that may be more sophisticated than the others, it’s best to keep the request limit per proxy server low.
Now, if you’ve determined the request rate per IP address per hour, here’s how you can calculate the number of proxy servers you need.
Suppose your scraper can scrape 50,000 web pages in an hour. Divide this number by the per-hour request rate. So, 50,000 divided by 300 will give you a little over 166. So you need at least 166 different proxy IPs to scrape websites successfully.
With the effective rotation of these IP addresses, you can easily send 50,000 requests distributed over 166 proxy server IPs.
How to Manage a Proxy Pool the Right Way

Building a personal web scraping proxy pool is only one part of the equation. With proper and active management of this pool, you still run the risk of seeing your IPs blocked, rerouted, or banned.
Just building a large pool of proxies may not be enough, considering how sophisticated websites have become at preventing scraping.
Here are some of the things you need to manage for your proxy pool:
Identifying bans
Regardless of how good your proxies are or how low the request rate is to circumvent rate limits, you need to take a preemptive approach to bans. Identifying the websites that have banned any IP you’re using can help you take a safer approach next time. In addition, it can also help you identify and fix any shortcomings in your proxies and scraper(s).
Location adjustment
You will need to set up your proxies to change geographical location as needed to target certain location-based websites. Whether configuring it to become an automated process or changing proxies manually, you need to use the right location IPs to target such websites actively.
Session maintenance
Many websites keep track of sessions, especially those with sensitive information and login functionality. Maintaining the session with the same IP is essential for such websites, as an IP change will refresh the session. You’ll need to configure the proxy pool to use the same proxy for such websites to maintain the session.
Retry errors
Set up the proxy IPs to try once again if they get an error or get redirected. Sometimes resending the request with the same IP can get through, even if it didn’t work the first time.
User agents
Effective management of user agents is essential for the effective management of proxies. User agents help avoid bans as their activity resembles real users.
Intentional random delays
Utilizing throttling techniques, especially creating delays in requests intentionally, can help avoid getting identified as a scraper. Remember how we discussed that there are often pauses in the number of requests for real human users? Well, randomizing delays helps achieve precisely that behavior.
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, compatible with all automation frameworks.
How to Use Proxies With Scraping Software

Now that you fully understand what a web scraping proxy is and why we need them, it’s time to discuss how you can integrate them with your scraping tool.
In most cases, you’ll be buying proxies from a provider who hosts the IP addresses through which you route the requests. It wouldn’t make sense to set up and maintain so many servers, regardless of the scale of scraping you’re undertaking.
Once your proxy pool is ready, integrating it with the scraping software is not difficult. You pretty much just need to do two things: routing the requests through the proxy servers and rotating IPs between those requests.
Passing requests through proxies
The first part would just require some code to tell the scraper to send the request to the proxy server, which, in turn, sends the request to the target website server.
However, this depends on the library the scraper is utilizing. As an example, here’s the code you’ll use if you’re using a Python library”
import requests
proxies = {‘http’: ‘http://user:[email protected]:3128/’}
requests.get(‘http://example.org’, proxies=proxies)
If you look at the proxy address above, you’ll see that it addresses several pieces of information like the IP address, port number, user, and password. Your proxy service provider will provide all this information for each of the servers in your proxy pool.
The best way to integrate the proxy URLs is to consult the documentation for your specific scraper software library. That will guide you on how to incorporate proxies into the software, as it’s a common practice for web scraping anyways.
Once you’re set up with the proxy URL integration, you should go ahead and test whether the proxy routing is working.
The website you can use for testing is ipinfo.io. This site tells the IP address from where the request is coming from. Send a request from the scraper to this site and see if it shows the IP address of the server proxy you just used.
If it’s the correct IP address, you’re good to go!
Rotating proxy servers
The first part is more accessible, but this second part is a little complicated. Nevertheless, it’s very important to make the best of your purchased proxies.
How frequently you need to rotate IPs depends on several factors, such as the request rate per IP.
The simplest way to rotate IPs is to make sequential requests and maintain a stack of proxies in memory. When one is used, it’s automatically moved to the end of the queue, and the next in the stack is used for the subsequent request.
This approach is much better than randomly assigning a proxy IP website because there’s always a chance of an IP address running again right after.
Things get complicated when you’re using multiple users for sending requests using the same proxy pool. As you don’t want parallel requests coming from the same IP address, it’s essential to use global IP tracking.
Detecting burned IPs
While the above two steps are ample for successfully using proxies for scraping, you should ideally also have a detection mechanism in place for identifying burned IPs. Burned IPs refer to the IPs that have exceeded the rate limit for a website and received an error.
The website may put the IP address for that particular proxy in a time-out, which can last for hours. Therefore, you need to utilize another IP address immediately to finish the task for that specific website.
As mentioned before, this is a crucial element of proxy management and allows you to avoid getting banned and reusing the same proxies once they can send requests.
Web Scraping Uses

Knowing the common web scraping use cases will help you understand even better why proxies are needed. Here are some of the typical enterprise applications of web scraping with proxies:
Price comparison
In the e-commerce world, pricing remains the ultimate bait to convert more customers. At the end of the day, many customers pay for the cheapest option. Today, it’s easier for them to find out where a product is going for the lowest price.
So many retail companies use web scrapers to keep an eye on the prices on their competitor’s websites. This way, they can adjust prices just in time to keep up with the competition. Many retail giants use scrapers for this very purpose.
Ad verification
A common scam on the Internet for enterprises and small businesses alike is run by advertising agencies that on paper offer to run advertisements on legit sites but don’t really do that. Instead, they run fake websites with fake traffic numbers. So the advertisement doesn’t go to the customers you need, and all the money is wasted.
Another purpose of ad verification through web scraping is to stop competitors from displaying ads about your business on shady websites. Yes, this is a common practice that may result in customers losing trust in your business because they saw the ad on an adult website.
Social listening
Scraping social media to monitor and observe opinions and comments about products or specific stories has become a norm. You know how some blogs publish funny or interesting tweets about particular incidents or trends? That is precisely what a scraper can do with social media accounts.
Similarly, companies selling a product or service can find out what people are saying about them on social media without manually searching.
SEO tracking
Web scraping also has some applications in Search Engine Optimization (SEO), where it helps extract keywords and tags from top Search Engine Result Pages (SERPs).
This can automate searching for relevant keywords and optimizing them in the content to improve search engine ranking. Otherwise, organically coming up with keywords can be a time-consuming process.
Tailored marketing
Everyone wants to market their product or service where it gets the most interest, and ultimately, the most number of clicks. With web scrapers, enterprises can tailor their marketing strategy to websites and platforms where their target audience spends the most time.
That’s not all; web scraping may also help retailers understand and improve sales on their own website.
Challenges With Using Web Scraping Proxies

While using a web scraping proxy is a viable option for enterprises, it’s not without its challenges. Any company using web scrapers, even with proxies, needs to address those shortcomings and challenges to ensure their investment results in a higher ROI.
Here are some challenges enterprises, in particular, utilizing web scrapers face:
Extraordinary volume of requests
Depending on the scale of the web scraping operation, just the number of requests made every minute, every hour, and every day can pose several challenges. As we have discussed, again and again, it’s becoming easier for websites to block IPs exceeding request rate limits.
This poses challenges for huge enterprises whose web scrapers are sending millions of requests per day. This translates into a considerable proxy pool as well, which warrants dedicated management and resources for that management.
They may need in-house developers to manage proxies actively. As a result, their expenditure on just proxies can increase dramatically.
Such a scenario requires more intelligent management of proxies and requests to increase efficiency and create workarounds for obstacles.
Accuracy of data
In general, this is more of a challenge for data scraping, as you can make the best of web scraping only if you’re getting useful data.
Managing proxies correctly to target suitable geographical locations is important. If your proxies are not correctly rotating the IP addresses based on location, they might end up scraping a website from the wrong location, which may not be useful to you.
This is easier to manage for low-volume scraping; it’s more complicated when the scale is more extensive.
Reliability of proxies
For enterprises with mission-critical data extraction needs, the reliability of a web scraping proxy is very important. As mentioned earlier, the quality of proxies also plays a vital role, even if you’re using the proxy scraper.
For instance, for those running scrapers for price comparison, a disruption for even a few hours can result in considerable losses in sales. This is usually the case with large-scale marketplaces and retailers, which generally handle vast sales volumes every hour.
How to Choose a Good Proxy Provider for Web Scraping

With web scraping being such a significant and vital application in different industries, the number of web scraping proxy server providers has consistently gone up. What does that mean? More choices, more confusion!
Understanding proxies, their uses in web scraping, and the challenges is part of the process to getting the best proxy scraper for your situation. For the second part, you need to know how to choose a reliable proxy provider for your unique application.
Size of proxy pool
The first and foremost thing to determine is the size of the proxy pool you’ll need for your particular web scraping project. This is because all proxy providers offer a wide range of plans with different proxy pool sizes and accompanying resources.
Knowing your needs would make it easier for you to narrow down your choices and consider only the providers who can actually provide proxy types and numbers you require.
Take your time to analyze your needs, not just for now but also for the near future.
Budget
There’s only so much you can spend on proxies alone. For any enterprise size, setting a budget before finalizing a proxy provider can come in very handy.
Depending on your budget, you may even be able to outsource your proxy pool management.
Of course, the budget-friendly way is to manage proxies yourself, which isn’t always possible. This brings us to the next important consideration.
Availability of technical expertise
As you already know by now, buying proxies is only half the work. The rest is managing the proxies effectively and efficiently to make the best of them. This requires technical expertise in the field. Lack of appropriate technical expertise can lead to buying proxies in vain.
If you have expert developers in-house, perhaps you can keep the management of proxies in-house only. However, if you lack the right technical expertise, you should go with the managed option, where the proxy provider does everything for you.
In most cases, even if you’re an enterprise with an in-house IT team, it may make sense to outsource the management. The management can be incredibly time-consuming for your team members, who may be better off spending this time on more critical operations.
Best Proxies for Web Scraping

If you’re looking for a premium proxy for web scraping, you should try Rayobyte proxies: the best proxy scraper for your business.
Rayobyte Residential Proxies are top-quality proxies based in several regions around the world. This allows you to target almost any location-specific website. More importantly, the rotation of IP addresses is automatic, which means you don’t have to change them manually or deploy code that does that for you.
The residential proxies are based in over 130 locations. This also allows your web scraper to circumvent tough blocking schemes, such as low request rate limits. These come with API access, making it easier to manage things if you decide to keep management in-house. Otherwise, you can use Proxy Pilot as well to make rotation and optimization easier.
For those looking for data center IPs, the Rayobyte Data Center Proxies are good proxies that provide reliable functionality for routing multiple requests. You can choose from a whopping nine autonomous number systems (ANS). The data centers are located in 27 Countries, and there are over 300,000 IP addresses. So this is an ideal solution for enterprises conducting large-scale web scraping.
As for performance needs, the data center proxies at Rayobyte can handle up to 25 petabytes per month. There are several plans and tiers within those plans to choose from, so you can find a solution that caters to your specific proxy needs. Also, you get unlimited bandwidth and unlimited connections no matter the plan you choose.
If you’re looking for the data without the need to scrape it yourself, we suggest using Rayobyte’s Web Scraping API for all of your enterprise scraping needs.
Rayobyte also offers a free trial for their proxy services, so you can try their custom dashboard among other offerings to see if it’s a good fit for your business. Regardless of the scraping software you use, integrating these proxies should be easy.
Conclusion

The primary purpose of using web scraping proxy servers is to mask the IP address of your source. However, as you’ve probably learned by now, they go beyond just hiding the IP address. If your business is not utilizing them, when used correctly, they will completely change the game for you.
Whether you’re scraping web pages on a small scale or at an enterprise level, using proxies can be highly beneficial. Of course, as the scale increases, so does management. However, the answer lies in choosing quality proxy providers who can also provide reliable management. Whether you’re looking for residential proxies, data center proxies, or mobile proxies, Rayobyte has a solution for you.
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, compatible with all automation frameworks.
The information contained within this article, including information posted by official staff, guest-submitted material, message board postings, or other third-party material is presented solely for the purposes of education and furtherance of the knowledge of the reader. All trademarks used in this publication are hereby acknowledged as the property of their respective owners.