Swift Web Scraping: Your “How To” Guide
What do you do if you need to collect a lot of information online without wasting time? If you’re like many savvy researchers, then you know there’s nothing more effective than web scrapers for bulk data collection. Still, if you’ve been using a prebuilt Swift web scraper, then you’ve probably noticed that results could be better.
There’s a big difference between off-the-shelf solutions and something you’ve custom-built yourself. If you want the best possible web scraping results, you should learn to create a tailor-made scraping program. Writing a scraper in Swift can be easy, especially if you’re already familiar with the language and the scraping process.
But what if you don’t know how to write a scraper? Don’t worry, because here is a complete guide on how to build a Swift web scraping program. You’ll learn why Swift is a good scraping option, how it compares to other scraping languages, and how to write a successful scraper. You’ll even learn the tools that make scraping easier and some best practices for leveling up your scrapes after you’ve got the basics down. But if you just need a refresher, use the Table of Contents to jump to the section you want.

What Is Swift and Why Write a Swift Web Scraper?

Apple created Swift in 2014 as a “robust and intuitive programming language” for building apps associated with its brand. Apple updates Swift regularly, so it’s always prepared to handle new web challenges.
But why would you want to use Swift when writing a web scraping program? Well, Swift is “open-source,” which means that anyone can use it. Apple encourages people to use Swift for programs like phone apps, but that’s far from the only use. Also, Swift runs on Linux, Windows, and Android, so it can be a good choice for anyone who wants to write an application.
Because Swift is relatively new and heavily designed for Apple systems, it’s not as well known as other languages like Python or Javascript. Therefore, there’s comparatively less talent available for writing in Swift than the alternatives. Still, within the Apple development world, Swift is essential. If you’re already working on Apple devices and applications, you or your team have most likely used Swift.
Scrape at Scale With Chromium
Playwright-compatible. Self-hosted. Built for real infrastructure.

Benefits of Swift web scraping
What makes Swift so easy and effective for scraping the web? There are three big reasons:
- Simplicity: Swift is easy to learn, write, and read. Whether you’re relatively new to programming or just to the Apple OS, Swift’s simple syntax makes it easy for anyone to get started quickly.
- Safety: The strict nature of Swift’s defined behavior requirements makes it easy for you to find errors early in the writing process, resulting in more secure, safer, and reliable down the line.
- Memory: Compared to other languages, Swift uses less memory, making it ideal for programs that will take up a lot of memory. Swift accomplishes this by using dynamic libraries. Essentially, Swift calls the libraries when they’re necessary instead of storing them entirely within the program. The use of these dynamic libraries makes Swift web scraping programs lightweight and perfect for apps and simple programs.
Swift vs. other programming languages
What if you’re not sold on using Swift? After all, there are many other programming languages people use to write web scrapers that work perfectly well. Swift is a great option, but it’s not always the right choice for a given developer. Here’s how Swift compares to JavaScript and Python, and when you should choose one or the other.
Swift vs. JavaScript
Swift pros:
- Native to Apple OS
- Easy to use and learn
- Open-source
- Code is easy to read
Swift cons:
- Few libraries
- Sometimes unstable due to updates
JavaScript pros:
- Excellent for online uses
- Extremely popular
- Versatile
JavaScript cons:
- Not designed for mobile
- Harder to learn than Swift
JavaScript is one of the more popular programming languages because it’s designed to run online operations in browsers, from autocomplete text suggestions to interactive forms. Since JavaScript is designed for online use, it’s great for collecting data from and interacting with websites. However, with systems like Node.js, you can also use JavaScript for offline programs or bots like web scrapers.
Still, JavaScript isn’t finely tuned for Apple operating systems in the way Swift is. Also, JavaScript is not as helpful for creating apps and mobile tools since that isn’t its primary purpose. Finally, JavaScript will be a little trickier to learn than Swift(though it’s not too challenging).
Verdict: JavaScript and Swift are close to equal in terms of their benefits and drawbacks. If you already know one or the other, stick with the language you know. But there is one exception: if you’re going to write a scraper that’s supposed to run on Apple devices, Swift is the best choice.
Swift vs. Python
Swift pros
- Excellent memory management
- Interoperability with C, Objective-C, and C++
- Designed for mobile
- Native to Apple OS
Swift cons:
- Sometimes unstable due to updates
- Limited talent pool
- Few libraries
Python pros:
- Lightweight
- Platform-independent
- Large libraries
- Open-source
Python cons:
- Not optimized for mobile development
- Uses a lot of memory
Python is an open-source, platform-independent programming language that’s designed to run on just about any system. It has thousands of libraries that you can use to make your web scraper better. Python is also lightweight and has a ton of talented programmers, making it a good choice if you want to write a program your team can easily update.
On the other hand, Python uses more memory than Swift, and it’s not ideal for mobile development. Finally, Python requires an API to connect with languages like C++ instead of being interoperable.
Verdict: Python is one of the most popular languages for web scrapers for a reason. If you’re writing your own scraper, you’ll find that Python has more resources and support than Swift on most platforms. However, if you’re going to primarily use your scraper on Apple devices, Swift is the better choice.
What to Do Before Writing a Swift Web Scraper (or Any Scraper)

Computers are extremely literal. When writing a program, you need to understand precisely what you want the computer to do. For example, you can’t tell a web scraper “collect all links” on a page because the scraper doesn’t innately understand what a link is.
If you want to write a great scraper in any language, you need to make sure you are completely clear on what you’re telling the program to do. You should do a little homework before you get started, especially if it’s been a while since you’ve programmed anything.
- Clarify the goals of your scrape. This should be a cinch if you’ve been web scraping for a while. Nonetheless, be quite specific on what result you want from your web scrape. Do you want all links from a page or only some? Which links do you want? Do you want any information that’s connected to them or just the raw URLs? These decisions will help you design the basic structure of the scraper.
- Refresh your HTML and CSS knowledge. Make sure you remember how HTML and CSS are structured. Web scrapers with SwiftSoup treat HTML as a ‘tree’ with different branches. Refresh your understanding of HTML trees and tags along with CSS descriptors. You’ll use these items to tell the scraper how to find the data you want.
- Study your target sites. Every website is unique. For example, the HTML structure of a Rayobyte blog is different from the structure of a Wiki site. If you’re going to write a web scraper, you should study your target sites and understand how their HTML trees are structured and how the data you want to scrape is tagged. Look for patterns, unique structures, and “sibling elements that you can make use of in your scrape. Make sure to write this information down so you can reference it later.
The Most Important Libraries (Including SwiftSoup) and Tools for Swift Web Scraping

Once you know the information you want to collect, you’re almost ready to begin. You just need to understand a few of the tools you’ll use while writing your Swift web scraper.
Apple and the open-source community have collaborated to produce excellent libraries and toolsets that will make your Swift web scraping process much easier. In particular, these five tools are essential to your scraper:
Xcode
The first and most important tool for any Swift program is Xcode. This is the Integrated Development Environment (IDE) that Apple has created for Swift. It’s specifically designed to run on Apple products, but it can also write Swift programs for any supported OS. You’ll need a Mac to use Xcode(but since you’re programming in Swift, you’re probably using one already).
Xcode is free and regularly updated, so the IDE is always being improved. Xcode is perfect for writing your web scraper in Swift because you can:
- Write code with easy versioning and error detection
- Monitor your program with syntax highlighting and code completion
- Test your code in different ways
- Collaborate with other programmers on the same program
- Build and test cloud-based programs
- Monitor crash reports
All together, Xcode is a powerful IDE that makes writing any Swift program easy. It’s also one of the only IDEs available for Swift. So basically, if you’re using Swift, you’re performing Xcode web scraping.
SwiftSoup
What is SwiftSoup? It’s a pure Swift HTML parser library. SwiftSoup is cross-platform, running on macOS, iOS, tvOS, watchOS, and Linux. SwiftSoup is designed to combine the best of methods like jQuery, CSS, and DOM to extract and manipulate data while remaining within the Swift language.
SwiftSoup was inspired by “BeautifulSoup” — another well-known HTML parser that runs on Python. SwiftSoup has many of the same functionalities:
- Find data
- Extract data
- Output clean HTML parse trees
- Manipulate HTML elements
Obviously, these are all valuable features for a web scraping program. Many Swift-based web scrapers choose SwiftSoup to scrape HTML protocols for exactly those reasons. Furthermore, you can install SwiftSoup through Carthage, Cocoapods, or the Swift Package manager.
Kanna
Another great Swift HTML parser is Kanna. The Kanna HTML parser can do just about everything SwiftSoup can do. However, Kanna offers the additional benefit of parsing XML, which can be helpful in many circumstances. Kanna may not be as easy to use as SwiftSoup, but it’s worthwhile if you need that XML functionality. You can choose either Kanna or SwiftSoup, but you can’t use both.
Alamofire
Every Swift-based web scraper should make use of Alamofire. This library is designed to make HTTP network requests easy. One of the fundamental elements of a web scraper is sending an HTTP request to collect the HTML you want to scrape. Alamofire has all the tools you need to request that data, handle authentication, and even connect with JSON parameters.
Alamofire was specifically built for Swift, making excellent use of the simplicity and power of the language. It’s built on top of Apple’s URL Loading System, including URLSession and URLSessonTask. Alamofire acts as an API wrapper, combining many useful pre-existing tools into a single, easy-to-use collection of commands and functions.
Another critical benefit of Alamofire is that it’s asynchronous. This helps keep the HTTP requests secure. You don’t need to reinvent the wheel on security or HTTP —you just need to use Alamofire scraping functionalities.
SwiftCSVExport
Your Swift web scraping program needs to have a way to export the data collected. Swift is largely designed to send information to apps, so it helps to have a tool to export that information in any other format. That’s where SwiftCSVExport comes in. This library handles the CSV conversion for you. All you need to do is use the library’s suggested code to export your results into a flexible .csv that can be opened with Microsoft Excel or Google Sheets.
Writing Your First Web Scraper: A Swift Tutorial

You’re armed with all the tools you’ll need to write a great Swift web scraper. Now you can finally sit down and start writing! This step-by-step Swift tutorial will show you how to write a basic web scraper that you can expand and customize to suit your needs.
Scrape at Scale With Chromium
Playwright-compatible. Self-hosted. Built for real infrastructure.
Before you start: Set up Swift and Xcode
If you haven’t written anything in Swift before, you’ll need to do a little setup before you get started. First, you’ll need to download Xcode to your computer. You can download the latest release from the Mac App Store. There’s a beta version and a stable version. Typically, the stable version is a better choice for a relatively simple program like a scraper.
Once Xcode is set up on your computer, you can download Swift Xcode and follow the instructions to get the language set up. Finally, open and save a new project for your scraper.
1. Download the tools you’ll need
You can start adding tools to your program that you want to use. In this tutorial, the libraries you’ll need are SwiftSoup, Alamofire, and SwiftCSVExport.
The easiest way to add new libraries to your Xcode projects is through CocoaPods. This is a valuable dependency manager that integrates libraries into Xcode projects automatically. If you don’t already have this program, you can download it from the CocoaPods site.
Libraries and other dependencies that run through CocoaPods are simply called “pods.” You add pods to your program by creating a Podfile text file in your Xcode project directory:
pod init
You’ll enter that into the program file and run it. This will generate a text file in which you can include the pods you want to use. Open the text file, then underneath “Pods for PROJECT_NAME” write:
pod ‘SwiftSoup’
pod ‘Alamofire’
pod ‘SwiftCSVExport’ , ‘= 2.6.0’
pod ‘SwiftLoggly’
Save the file and close it, then return to your Xcode window. You can get rid of the line pod init and replace it with:
pod install
This will generate a new file: PROJECT_NAME. xcworkspace. That’s the file you’ll use to write the rest of your program.
2. Get the HTML
With everything installed, you can finally start writing the program properly. The first step of the scraping process is collecting the HTML from the site you want to scrape. Alamofire makes it easy for you to create a function for grabbing the HTML:
func scrapeRayobyte() -> Void {
This names the function “scrapeRayobyte” and also states that the function won’t return a specific value. Next, tell Alamofire what to collect:
Alamofire.request(“https://rayobyte.com/blog”).responseString { response in
let code = response.result.value
}
This is the basic code that every Alamofire request uses to target a specific URL. The first line instructs Alamofire what site to visit, and the following line converts the HTML found there into an object that will be used to feed into SwiftSoup.
3. Parse the collected data
Now you’ll run the HTML you’ve collected through SwiftSoup to parse it into something the program can read:
let document = try SwiftSoup.parse(code)
This instructs the program to parse the code object with SwiftSoup. It converts the HTML into a parsing tree that your program will be able to read.
What do you want to do with the HTML? At this point, your initial research will come in handy. Use the information you collected about your target sites to tell SwiftSoup what information it should collect. For example, if you’re trying to collect the links to blog posts on the Rayobyte site, you could type:
let link = try document.select(“Read More”).first()!
var item = link
This will find the first element on the page that includes “Read More” within it, which is the “a href” element. It also designates all siblings of the element, or similar elements at the same point on the HTML tree, as the variable “item.”
Next, set up a dictionary to collect all of the links you’re about to collect.
var myDictionary:[Key:String]
var keys = myDictionary.keys
var values = myDictionary.values
Now you can begin collecting all the information you want. In Swift, the easiest way to do this is with a while loop:
while true {
guard let bloglinks = try item.nextElementSibling()
else { break }
myDictionary[“Collected links”] = bloglinks.tagName()
if bloglinks.tagName() != “a” {
break
}
This loop tells the program to find all the sibling elements to the one you identified earlier. However, the loop will end if a sibling doesn’t have the tag “a” that indicates a link. Furthermore, this loop prevents you from collecting junk data and adds each sibling to the dictionary “myDictionary” to reference it later.
4. Save the results in a file
For your scraper to be useful, it needs to output all the information found in your preferred file format. JSON and .csv files are both popular. Many developers even use Xcode to produce apps that display the results. However, for simplicity’s sake, in this Swift tutorial, you’ll be outputting your data into a .csv file.
Using .csv files gives you the most flexibility. A .csv file can be used in all popular spreadsheet programs, from Microsoft Excel to Google Sheets. You can even open .csv files with a text file program to directly check what your program has output. This is how you can start scraping data into Google Sheets with Xcode and Swift.
Now, it’s finally time to use the SwiftCSVExport pod you added at the very beginning of the program. You’re going to use the dictionary you created with all your links to print to the file:
let headerRow = [“CollectedBlogLinks”]
let data:myDictionary = NSMutableArray()
data.add(myDictionary.values)
This designates what your header row will be called and tells the program what to add to the file.
Next, generate the .csv file itself using SwiftCSVExport’s recommended code:
let writeCSVObj = CSV()
writeCSVObj.rows = data
writeCSVObj.delimiter = DividerType.comma.rawValue
writeCSVObj.fields = header as NSArray
writeCSVObj.name = “scraperesults”
This explains how the file should be formatted. Now, you’ll write the results to the file:
let result = exportCSV(writeCSVObj);
if result.isSuccess {
guard let filePath = result.value else {
print(“Export Error: \(String(describing: result.value))”)
return
}
self.testWithFilePath(filePath, rowCount: data.count, columnCount: header.count)
print(“File Path: \(filePath)”)
Finally, you’ll read the file to make sure it is exported correctly and then save it:
let readCSVObj = readCSVObject(filePath);
loggly(LogType.Info, text: readCSVObj.name)
} else {
print(“Export Error: \(String(describing: result.value))”)
}
Once your data is saved to a .csv file, you’re all set to open it in Google Sheets or Microsoft Excel. Just go to your preferred spreadsheet program use it to open the .csv file with your scraping results. The boxes and tabs should automatically fill with the data you’ve collected.
The final product
You’ve done a lot of work to get to this point. Now see what the program will look like all in one place after you’ve generated the Podfile:
func scrapeRayobyte() -> Void {
Alamofire.request(“https://rayobyte.com/blog”).responseString { response in
let code = response.result.value
}
let document = try SwiftSoup.parse(code)
let link = try document.select(“Read More”).first()!
var item = link
var myDictionary:[Key:String]
var keys = myDictionary.keys
var values = myDictionary.values
while true {
guard let bloglinks = try item.nextElementSibling()
else { break }
myDictionary[“Collected link”] = bloglinks
if bloglinks.tagName() != “a” {
break
}
let headerRow = [“CollectedBlogLinks”]
let data:myDictionary = NSMutableArray()
data.add(myDictionary.values)
let writeCSVObj = CSV()
writeCSVObj.rows = data
writeCSVObj.delimiter = DividerType.comma.rawValue
writeCSVObj.fields = header as NSArray
writeCSVObj.name = “scraperesults”
let result = exportCSV(writeCSVObj);
if result.isSuccess {
guard let filePath = result.value else {
print(“Export Error: \(String(describing: result.value))”)
return
}
self.testWithFilePath(filePath, rowCount: data.count, columnCount: header.count)
print(“File Path: \(filePath)”)
let readCSVObj = readCSVObject(filePath);
loggly(LogType.Info, text: readCSVObj.name)
} else {
int(“Export Error: \(String(describing: result.value))”)
}
You can customize this code however you want. Some people like to collect more than one piece of information from a site, while others prefer to save their information and present it in an app. Don’t be afraid to explore the world of Swift to see how you can make your scraper work better for your needs.
Best Practices for Swift Web Scraping

Once you’ve written a basic scraper, you can start exploring ways to improve it. Following best practices will make any scraper safer and more successful. The following tactics and techniques will help you gather data more effectively and protect your scraper from getting blocked by the sites you’re studying.
Follow laws regarding privacy and intellectual property
Collecting data is great, but you need to think before you scrape. There are circumstances when scraping information can be illegal. For example, the GDPR makes it unlawful to scrape personal information about EU citizens unless you have explicit consent or use it for a few specific purposes. Other privacy laws, like CalOPPA, also legislate what you can do with personal information. In general, it’s best to avoid scraping private or identifying information, such as names and email addresses, entirely.
Similarly, you should be vigilant about collecting copyrighted data. You are allowed to study copyrighted data using web scrapes (this is considered “Fair Use”), but you can’t use the data on your site. For example, you can’t scrape someone else’s product pictures and use them on your website.
If you’re just using web scraping for research, you probably aren’t violating any laws. Still, it’s always a good idea to check before you get started.
Be polite to the sites you visit
Scraping can put a lot of stress on a website. You may accidentally crash the server if you send too many HTTP requests to a site that’s not prepared to handle them. If the site goes down, your scape will be ruined.
Site owners are aware of the potential for server crashes and have security measures in place to ban visitors who put their servers at risk. Be polite with your scrapes as a matter of good etiquette — and it will prevent the site from banning your scraper, too.
So, how can you be polite with your scraper?
- Always check the site for a “robot.txt” file and an API. The robot.txt gives instructions about how to interact with a site, so it’s good form to follow those guidelines if provided. Furthermore, an API can prevent you from needing to scrape the site altogether. Many websites offer APIs that include all the scrapable information. You simply connect to the API and select the information you want to download. Thus, you don’t have to run an API, and the site owner doesn’t have to worry about huge amounts of traffic.
- If there’s no robot.txt or API, you should scrape during off-hours. A site based in the US will probably be the least busy during the early morning hours. Schedule your scrape for the middle of the night to avoid putting even more stress on servers when they’re already busy.
- Sign your scrapes. As if you were providing a business card, signing your scrapes lets the site know who you are and why you were there. In addition, singing helps the site administrator worry less about the sudden spike in traffic.
Implement headless browsers
The scraper you wrote earlier doesn’t use a browser to access the internet. Instead, the scraper relies on SwiftSoup to access the web. However, there are some benefits to routing your scrape through an actual browser instance.
Without a browser instance, some websites won’t load all of their content. Many modern sites heavily rely on JavaScript and AJAX calls to provide information without reloading the page. These items are triggered by a browser, not by a simple HTTP request. By using a browser, you can collect more information more easily.
You can get more benefits by using “headless” browsers. These are browser instances that run all the same processes as a normal browser without having to load the GUI. Headless browsers help you walk the line between loading all the elements of a page, including JavaScript and dynamic CSS, without sacrificing speed. To make your browser instance headless, you can use the Erik library and the following suggested Swift code:
Erik.visitor(url: url) { object, error in
if let e = error{
} else if let doc = object {
}
}
This will replace the code using SwiftSoup to access the page. You’ll insert your HTML inspection with swift after the else if command.
Slow down your scrapes
If you’ve never built your own scraper before, you may not realize that it’s possible to scrape too fast. In fact, this is one of the most common ways website security features identify bots. Scrapes can visit dozens of pages per minute, stressing a server and forcing it to block your program in self-defense.
You can slow down your scrape by implementing a wait period element. This can be a sleep command or a dispatch_after block. Dispatch_after is usually more effective. It looks like this:
let seconds = 2.5
DispatchQueue.main.asyncAfter(deadline: .now() + seconds){
}
Slowing your scrape will also help you avoid traps, like hidden CAPTCHAs. When your scraping bot accesses a site too many times per minute, it can trigger security measures that display CAPTCHAs before loading the site. Even the best bot isn’t going to quickly or easily solve a CAPTCHA. By slowing down a little, you can avoid these hidden CAPTCHAs and keep your scrape running smoothly.
Add human scraping patterns
A scraping program reveals itself by scraping too fast and doing exactly the same thing on every page it visits. Add a little randomness to your scraper’s behavior so that it looks more human and reduces the number of blocks you face. An easy way to humanize your scraping pattern is to randomize the time between each page.
To accomplish this, replace the integer in the above Dispatch_after code:
let seconds = Int.random(in: 1…<10)
Integrate proxies
The best way to protect your Swift web scraper is to use a proxy. Proxies protect your IP address from being detected by shielding it behind a different address. That’s essential if you’re performing larger scrapes.
When a site detects a bot that it wants to stop, it will usually block the bot’s IP address. This is a big problem if the IP address is also your regular address. You won’t be able to access the site at all for the duration of the block, even if you’re not using a bot.
Proxies prevent blocks from happening. If a site detects the scraper, it will block the proxy IP address and not yours. You can continue your scrape by swapping in a new proxy and never risk your actual address.
Scrape at Scale With Chromium
Playwright-compatible. Self-hosted. Built for real infrastructure.
What Proxies Work Best for You?

When implementing proxies in your Swift web scraper, make sure you’re choosing the right ones. One of Swift’s most significant benefits is how Apple supports it. It would be a shame to waste that support by using an insecure or unstable proxy.
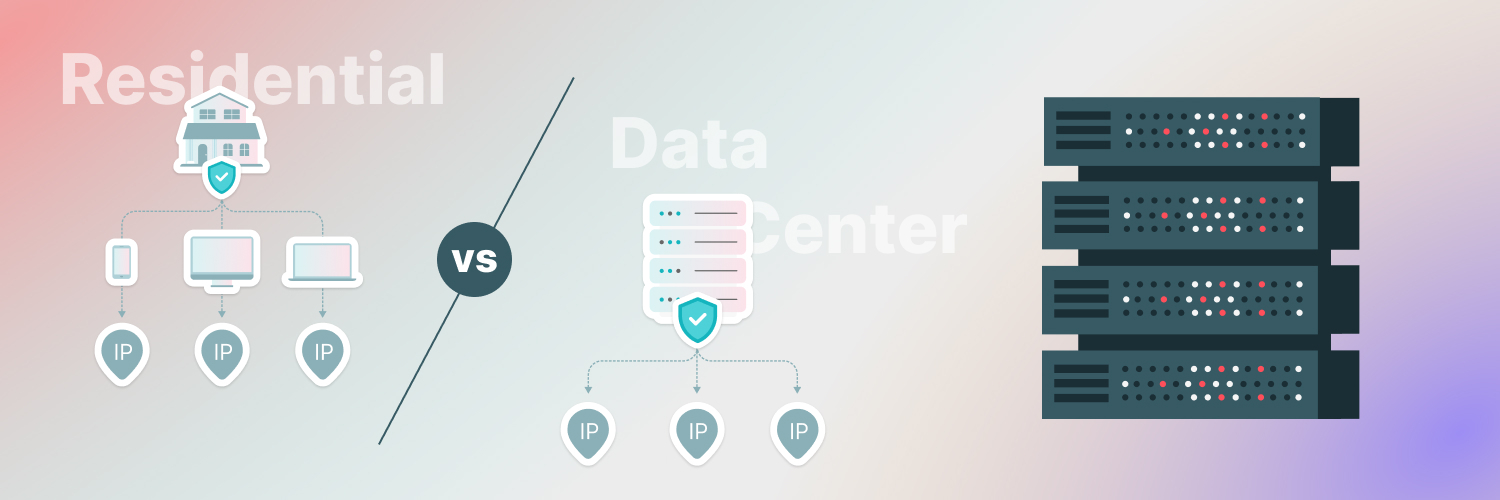
There are two primary types of proxies from which you can choose:
- Data center proxy: generated by a company with a collection of servers, making them more common and cost-effective. However, they can also be identified by website security features quite easily.
- Residential proxy: IP addresses connect to a home address. The ISP assigns these only to homes, making them a big investment with few available. However, they are harder to detect and less likely to get blocked.
Both types of proxies can be “rotated,=” or swapped out with other proxies. A rotating proxy is a collection of proxies that are regularly exchanged. One proxy is never used for too long, so sites can’t connect strange behavior to a specific proxy IP address and block it. As opposed to residential, rotating data center proxies typically require more proxy addresses to remain functional.
So, what’s the ideal proxy for web scraping? A rotating residential proxy is your best option. These proxies are the safest and most secure options on the market. Rayobyte will help you learn more about residential proxies and understand their full benefits.
Conclusion

There you go! You’ve learned what Swift is for, how to write a solid Swift scraper, and how to improve your scraper when ready. Now, you can start refining your scraper into a program that works for you.
Get started today by getting your secure, reliable residential proxies from Rayobyte. When you work with the best of the best, you’ll be keeping your Swift web scraping program safe from blocks or bans while protecting your IP address as well.
The information contained within this article, including information posted by official staff, guest-submitted material, message board postings, or other third-party material is presented solely for the purposes of education and furtherance of the knowledge of the reader. All trademarks used in this publication are hereby acknowledged as the property of their respective owners.