Ultimate Guide To Selenium Web Scraping And Proxies
The saying goes that if you want something done well, you need to do it yourself. That’s not always true, but designing custom solutions is definitely easier for the person who needs them. For example, if you’re performing web scrapes, understanding how to write a Selenium web scraping program can help you collect more and better data than ever before.
Selenium is one of the most helpful tools for performing web scrapes. It’s not a one-stop-shop solution, but it offers unique capabilities that simplify many aspects of the scraping process. By integrating Selenium into your web scraper, you can perform more and better scrapes in less time.

How to Use Selenium: What It Is and How It Works

Selenium is an open-source suite of tools for automating web browsers. It was originally developed in 2004 under the name “JavaScriptTestRunner,” but it has since expanded to cover much more than just Java.
Selenium supports testing in most popular programming languages, including C#, Groovy, Java, Perl, PHP, Python, Ruby, and Scala. It’s primarily intended to help programmers test their web applications and spot errors.
Today, the framework called Selenium consists of a collection of tools that are each designed to perform web test automation in a different way:
- Selenium IDE: The Selenium IDE (integrated development environment) is an environment specifically created to write Selenium tests. It can be connected to browsers through add-ons. It also allows users to record and edit tests. The IDE uses “Selenese,” a unique language that includes specific commands for in-browser actions as well as retrieving information.
- Selenium Client API: A collection of APIs for Java, C#, Ruby, JavaScript, R, and Python that allow people to write tests in these languages instead of Selenese. The originals are starting to be phased out in favor of Selenium WebDriver APIs, but they’re still used and supported.
- Selenium Remote Control (RC): This is one of the oldest forms of Selenium. It’s a server written in Java that commands the browser via HTTP. Most modern Selenium implementations use Selenium WebDriver instead.
- Selenium Grid: Server that permits Selenium to run tests on web browser instances on remote machines. Allows for multiple machines to run tests at the same time, speeding up the process.
- Selenium WebDriver (Selenium 2.0): The successor to Selenium RC that doesn’t require a dedicated server. Instead, WebDriver can directly start and control a browser instance or multiple if connected to Grid. It is significantly lighter-weight than Selenium RC and performs fewer HTTP calls. When people refer to “Selenium,” they’re typically referring to Selenium WebDriver.
Scrape at Scale With Chromium
Playwright-compatible. Self-hosted. Built for real infrastructure.

The Benefits of Using Selenium for Web Scraping

So, that’s what Selenium is. What does that have to do with web scraping? Quite a bit, actually. Just because Selenium wasn’t designed for scraping doesn’t mean it’s not useful.
Web browser automation
In particular, Selenium offers some unique web browser automation abilities. Since it’s specifically designed to perform browser actions automatically, it has built-in features that make it easy to use your preferred browsers to run web scrapes.
Data collection from asynchronous sites
Selenium takes control of browser sessions, which makes it a solid tool for collecting data from sites that load asynchronously or that are otherwise heavy on JavaScript elements. The tool can scroll through the page, causing the site to perform AJAX calls and load more information.
Scraping automation
Similarly, you can use Selenium to automate scrapes that travel through links on a site. For example, you could collect all product titles on a retail site by going to the first page of the catalog, scraping the titles, then using Selenium to click the “next” link and travel to the next page. You can set this to repeat until there’s no longer a “next” button, indicating you’ve visited all the pages.
Disadvantages of Using Selenium for Web Scraping

With all those helpful features, you may be considering writing a web scraper entirely in Selenium, using Selenese. However, that’s not actually a great idea. It’s theoretically possible to write a web scraper entirely in Selenese, but almost no one actually attempts it.
Why? Two reasons. First, Selenese just isn’t very powerful on its own. While it’s excellent for testing sites, it’s not as useful for writing a robust web scraper. It has a large library of commands for finding elements on a screen but almost no tools for manipulating the data it collects. It’s designed for interacting and monitoring sites but not necessarily collecting huge amounts of data.
Second, there are so many languages that work with Selenium and have additional uses that writing the code entirely in Selenese isn’t necessary. You can use Selenium WebScraper APIs to connect Selenium to so many other languages that it’s easier to use those alternatives and all the benefits they provide.
Selenium Web Crawlers vs. Other Solutions

It’s clear that while Selenium has many uses, it’s not the best solution for web scraping. There are other tool sets that are more effective at handling the tasks required to perform a solid scrape.
Two of those tool sets are Python and JavaScript. Both of these languages are better suited to running online and handling data collection. Here’s how Selenium compares to these alternatives and why it might be a good choice to switch.
Selenium and Node.js
According to its hub site, Node.js is an “asynchronous event-driven JavaScript runtime, […] designed to build scalable network applications.” It’s designed to support JavaScript even outside of a browser. Like Selenium, it’s a framework, but unlike Selenium, it supports both online and offline processes.
Node.js is intended to run JavaScript in particular, while Selenium can support many languages. If you want to use JavaScript for your web scraping, it’s better to use Node.js than pure Selenium. Node.js is easier to use, easy to scale, and it’s beginner-friendly. Plus, it’s optimized for JavaScript from the beginning.
Still, there is an API that connects Node.js and Selenium. If you’re set on using Selenium, you can integrate the two.
Selenium and Python
Python is a specific language supported by Selenium. Unlike Selenese, Python is an incredibly flexible language that can perform both online functions and significant data storage and manipulation. Python environments can support online and offline functions as well as printing results to a file.
Another benefit of Python is that it’s easy to learn and widely applicable. If you’re learning a new language to write your scraper, Python will be more useful in the long run.
Selenium does integrate neatly with Python, though. That means that Selenium is a great tool to use with Python. Still, if you’re going to choose one or the other, it’s probably easier to start with Python and choose whether to add Selenium from there.
How to Scrape with Selenium

If you’ve decided that Selenium is the right choice for you, then you have some preliminary work to do. You can absolutely write a functional web scraper with Selenium as long as you’ve done your research first.
Decide what information you want to collect. There’s a lot of information available online. Even a single site can contain terabytes worth of data. Before you dive into writing a web scraper, you should take a moment to figure out what information you actually want to collect. This is a fundamental element of writing your scraper that will help you refine it and minimize the garbage data you collect.
Understand HTML and CSS. The other fundamental element of scraping is understanding how HTML and CSS work together to generate web pages. Refresh your memory on different tags, selectors, and elements. Scrapers read the HTML and CSS to find the information you want them to collect. If you want them to read this correctly, you’ll need to understand the code yourself.
Research the sites you want to scrape. Now, you’ll combine the two elements above into a single item. Since you understand HTML and you know what information you want to gather, go visit the sites you’re going to target and do some investigating. Explore the page code with browser developer tools. Figure out where on the page the data is found and how it’s stored. Once you’ve got that information, you can actually start writing a program that works.
Scrape at Scale With Chromium
Playwright-compatible. Self-hosted. Built for real infrastructure.
How to Write a Selenium Web Scraping Program

So, you’re sure you want to use Selenium to scrape sites. With the right tools, this is easy. The following step-by-step tutorial will walk you through the process of writing a Selenium web scraping program with your chosen language.
Note that this walkthrough doesn’t cover writing a web scraper in Selenese. Instead, it uses Selenium Client APIs to run Selenium WebScraper with other coding languages.
If you’re ready to get started, let’s dive in.
0. Choose your language
Since Selenium is a framework, not a programming language, you can’t just load it up and go. You’ll need to choose a programming language in which to write your code. Think of Selenium as the car you use to get somewhere. The car still needs a driver, and that’s the program that you’ll write.
Of the languages that Selenium supports, Python is the best for writing web scrapers. Python is a flexible, easy-to-learn language that’s extremely effective at web scraping. Running Python with Selenium is an excellent way to make the most of both tools. As such, the rest of this tutorial will assume you’ve chosen to use Python.
Working with Python in Selenium is easy. You’ll need to install Python on your computer. You can follow the instructions on Python.org to get the right version of Python for your operating system.
1. Quickstart Selenium
Next, you’ll need to install Selenium and Selenium drivers. All you need to do is go to the command line and type in:
pip install selenium
This will add the Selenium package to your computer.
Next, you can go to your chosen IDE and start writing your actual program. IDEs like PyCharm and Visual Code Studio work great for this. The Selenium IDE doesn’t work as well since it only supports Selenese. Once you’ve opened up your IDE, create a new file and type at the top:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
These two commands are essential. The first ensures that you’re using WebDriver to perform your scrape. The second is an invaluable bit of Selenium. It allows you to use commands to press keys in a browser instance. This will allow you to hit “enter” to log into a page, for example. It also allows you to submit strings to text fields such as the username and password field, which will be useful later.
For this tutorial, it will help if you import one other library, too. Python has a built-in csv library that’s designed to make it easy to print your data to .csv files. That’s simple:
import csv
2. Choose a browser
The browser you choose to use will depend on your preferences. One of the nice things about Selenium is that WebDriver supports five different browsers, including Chrome and Firefox.
Find a browser based on your preferences and the sites you want to scrape. Many sites are optimized to run on certain browsers, which makes these browsers better choices for your scraper. In this tutorial, you’ll install Firefox.
driver = webdriver.Firefox()
This command opens up an instance of Firefox in its normal, “headed” form. When the program runs, a Firefox browser window will pop up, and you’ll be able to see the scrape as it’s performed.
You’ll also need to tell the browser what site to load. The simplest option is to insert a single URL, like so:
driver.get(‘https://rayobyte.com/blog/’)
This will pull the site you care about and target it in for a scrape. If you want to scrape multiple URLs in a single session, you should use the Python list function. You can add the following before the driver.get command.
URL = [“https://rayobyte.com/blog/”, “https://rayobyte.com/blog/2/”, “https://rayobyte.com/blog/2/”]
i = 0
while i < len(URL):
Then replace the driver.get command with this:
driver.get(URL[i])
i = i + 1
This will let you loop through all the URLs in your list and repeat the rest of the program for each.
3. Use Selenium functions to locate elements
So far, you’ve told Selenium what URLs to visit through Python code. Now it’s time to tell it what to do on those pages. Selenium offers a number of functions that you can use to find specific elements on a page. The research you did earlier to figure out how information is stored on the sites you’re targeting will come in handy now.
For example, let’s look at the Rayobyte blog page. Let’s say we want to collect all the titles of the blog articles on the first page. Looking at the HTML, these are stored under H3 tags. One way we could find these would look like this:
h3 = driver.find_element_by_name(‘h3’)
Now we need to tell the program what to do when it finds those H3 tags. A good way to collect them is by adding them to a list:
for title in h3:
title_list.append(title.text)
driver.quit()
This is a short for loop that creates the list “title_list” and then tells the program to add the text within each h3 tag to this new list. Meanwhile, the driver.quit() command tells the WebDriver to stop and close once it’s run out of h3s and allows the program to go to the next part of the code.
What if you want more than one piece of information? For example, what if you want both the titles of the blog articles and a link to those articles? That gets a little more complicated. After all, there are lots of links on this page. Just searching for links will bring a lot of “garbage” (unwanted) data.
First, we’ll need to use the right Selenium command:
title_links = find_element_by_link_text (‘Read More’)
for link in title_links:
link_url = find_element_by_tag_name(‘a’)
link_list.append(link_url.text)
driver.quit()
This code identifies all the “Read More” sections, then checks those seconds for “a” tags, which identify links. Finally, it adds those links to the list “link_list.”
4. Print results to a file
The final step of a good web scraping program is converting the data you’ve collected into a useful format. For example, you can send all of the data you’ve collected to a .csv file, which you can use in Microsoft Excel or Google Sheets.
Now you’ll finally use the csv library we imported at the beginning of the program.
with open(‘blog_articles.csv’) as f:
write = csv.writer(f)
write.writerow(title_list}
write.writerow(link_list}
This will write each list to its own row in the resulting .csv file. The result will be a neat collection of titles above the links to which they correlate.
The final product
That’s a lot of information. Don’t worry if you got a little lost. Here’s what the program looks like all in one place:
pip install selenium
import csv
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
URL = [“url1”, “url2”, “url3”]
i = 0
while i < len(URL):
driver.get(URL[i])
i = i + 1
h3 = driver.find_element_by_name(‘h3’)
for title in h3:
title_list.append(title.text)
title_links = find_element_by_link_text (‘Read More’)
for link in title_links:
link_url = find_element_by_tag_name(‘a’)
link_list.append(link_url.text)
driver.quit()
with open(‘blog_articles.csv’) as f:
write = csv.writer(f)
write.writerow(title_list}
write.writerow(link_list}
As a whole, the scraper:
- Cycles through a list of URLs
- Searches each page for all the h3 headers and collects their text
- Searches each page for all the blog post links and collects their text
- Prints both of those data types to a spreadsheet file
It’s a great foundation for collecting data and gives you plenty of room to expand and customize based on your needs.
The 7 Best Practices to Use Selenium to Scrape Data

A basic scraper is great, but it’s just the first rung on the ladder. As you get used to performing scrapes with a custom program, you’ll start looking for ways to improve.
The easiest way to make your scraper even better is to start implementing some best practices. The following nine best practices are easy and effective ways to make sure your web scrapes are effective, legal, and unlikely to get blocked.
1. Pay attention to the GDPR
Scraping sites is a great way to collect data, but you should always make sure you’re doing so legally. In most cases, you shouldn’t have a problem following GDPR rules during your scrape. In general, the GDPR only relates to individual people’s personal data. As long as you’re not collecting the private information of EU citizens, then you should be in the clear.
Specifically, you may not collect information like:
- Names
- Dates of birth
- Email addresses
- Physical addresses
- IP addresses
- Phone numbers
- Bank and credit card information
- Employment data
- Medical details
There are only two exceptions to this. If you have consent from everyone involved in the scrape, then you may collect this information. Otherwise, you must need the information to fulfill a contract or comply with laws in order to collect and store it.
This means that you can’t scrape social media sites for people’s individual information. However, you can scrape sites for businesses’ information or for comments made by individuals as long as you don’t save who said them.
2. Implement headless browsers
A great way to speed things up is to use a headless browser. Essentially, instead of using Selenium to load a browser instance that fully loads the GUI, it loads all of the processes except the GUI. The GUI is known as the head, so without it, the browser is “headless.” The browser is still running, and the actions are still being performed. They just aren’t visible on the screen.
Headless browsers speed things up for one simple reason. It takes a lot of calculation time for a computer to translate code into images. When the computer doesn’t have to render anything, it can perform all the same functions in significantly less time.
You can make your Selenium session run a headless browser by using the following code:
from selenium.webdriver.firefox.options import Options
firefox_instance = Options()
firefox_instance.headless = True
This will load a completely headless instance of the same Firefox browser you were already using in the Selenium example above.
3. Don’t scrape too fast
Selenium web scraping Python programs are great tools for performing scrapes, but they have one flaw: they are sometimes too fast. While it’s great for scraping researchers like you if your scrape concludes quickly, it’s not always great for the sites you target.
For instance, smaller sites generally have fewer servers. They aren’t designed to support large amounts of traffic, especially all at once. If you’ve created a super-efficient Selenium web scraper, it might be visiting different pages on the site hundreds of times a minute. That could actually crash the site.
A crashed website is no use to your scrapes. It’s considered good etiquette to limit your scraper or slow it down, so it doesn’t damage the sites it visits. You can use Selenium’s WebDriverWait() command to avoid this. A basic use of this feature would look like this:
slowdown = WebDriverWait(driver, 5)
This tells the driver to wait five seconds before continuing to run, helping you avoid overwhelming the site you want to study.
4. Scrape during off-hours
Another way to make your scrapes a little more polite is to wait until off-hours to start running your programs. No matter what, your scrape will add more traffic to a site’s servers. If you’re going to be performing a scrape of more than 10 pages, it’s polite to wait until off-hours to run it.
Think of it like placing a massive order at a restaurant. If you show up with a party of 20 people during the dinner rush, the restaurant will be overwhelmed. On the other hand, if you visit at 3 pm, the restaurant probably won’t be as busy, and you’ll get all your food. The same thing goes for scrapers. Ideally, run your scrapes in the small hours of the morning, when most sites see the least traffic.
5. Use human behaviors
This tip is more for your sake than the sake of the websites you visit. Many sites, afraid of getting crashed by inconsiderate scrapers or hackers, implement security measures to spot and block bots. One of the most common ways they identify bots is through their behaviors.
Most bots will always click on links in the same spot, visit pages for a specific length of time, and rarely or never scroll or move the mouse on the screen. If your web scraping program acts like that, it’s more likely to get spotted and blocked. That can ruin your scrape permanently.
Luckily, Selenium makes it easy to avoid this. The rich suite of commands for interacting with a browser page gives you all the tools you need to make your browser act more human. The Selenium.dev site has a large amount of documentation on how to implement random movements to perform tests that you can also use to make your web scrape appear less robotic.
6. Rotate your user-agent
Another way site security systems try to spot scrapers is by checking the user-agent. This string identifies who’s actually visiting a site. Many scrapers have suspicious user-agents, but it’s relatively easy to mask them with Selenium.
To accomplish this in Firefox, you want to set a new variable for “general.useragent.override” in the browser.
user_agent = webdriver.FirefoxProfile()
user_agent.set_preference(“general.useragent.override”, “new user-agent”)
driver = webdriver.Firefox(user_agent)
This code instructs the Firefox instance to run using your preferred user-agent instead of the default. This can help your scrape seem less suspicious.
7. Implement quality proxies
If you’re trying to protect your scraper, it’s critical to use good proxies in your program. A proxy acts as a disguise for your IP address. When most sites block a scraper, they specifically block the scraper’s IP address. These blocks may be temporary, or they may be permanent. If you’re using your actual IP address without a proxy, you’re putting yourself at risk. You could get permanently blocked from the sites you want to study.
That’s why proxies are so important. The proxy routes all your traffic through a different IP address instead of your own. If a site does detect and try to block your Selenium scraper, it will block the proxy IP address, not your own. You can just swap in a new proxy and keep scraping without worrying about permanently losing access to the sites you care about.
Choosing the Best Proxies for Selenium Web Scrapers

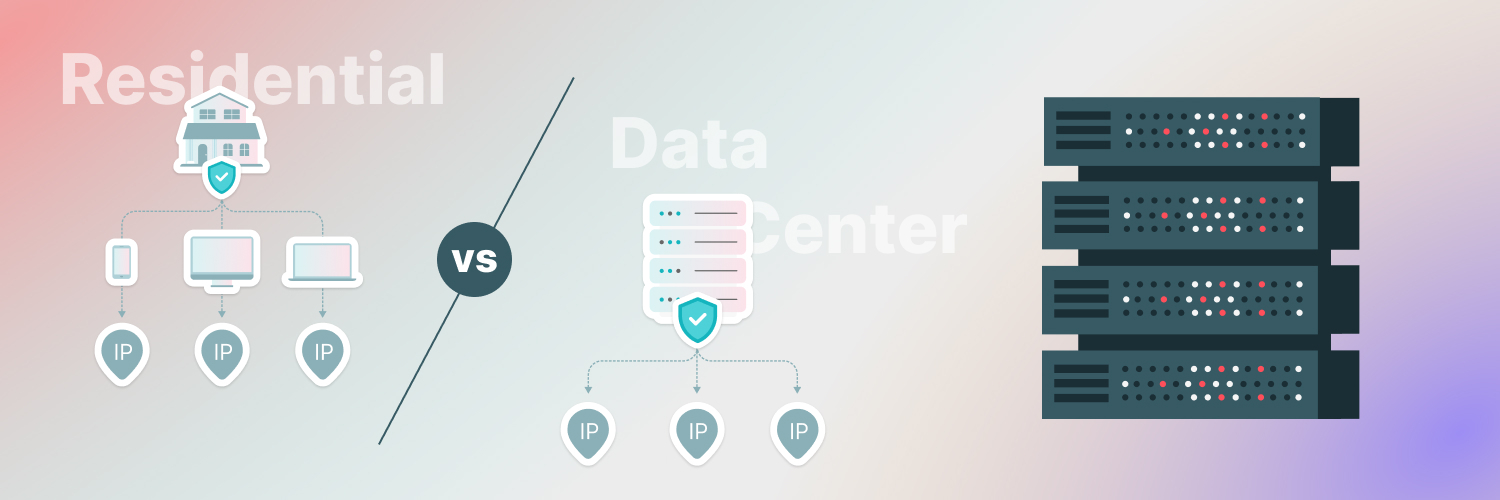
If you’re looking for the right proxies for your Selenium scraping program, you should understand the options available. There are two main types of proxies available: data center and residential proxies.
Data center proxies
Data center proxies are IP addresses generated in a single data center full of servers. These proxies are the less expensive but less reliable solution.
Residential proxies
The alternative is residential proxies, which are IP addresses that are associated with a real Internet Service Provider. These proxies look like they’re coming from someone’s home, so they’re more expensive but more reliable.
Rotating residential proxies
One way to make both types of proxies more secure is to use rotation. Rotating proxies are proxies that automatically swap out at regular intervals. Your scraper is hidden behind a different IP address every few minutes, making it almost impossible for the site you’re visiting to track it. Both data center and residential proxies can rotate.
If you’re looking for the most reliable, secure, and trustworthy proxies for your web scraper, the answer is to use rotating residential proxies. Rayobyte offers the industry’s best rotating data center proxies and rotating residential proxies. If you want to explore the proxy options available to you, you can learn more about residential proxies from Rayobyte.
Scrape at Scale With Chromium
Playwright-compatible. Self-hosted. Built for real infrastructure.
Solving Common Problems When Scraping with Selenium

No matter what scraping solution you use, your first few attempts will likely run into a few errors. The internet is a complicated place, after all. As you run more scrapes, you’ll discover the most common problems you face and have the opportunity to fix them.
Here’s a quick cheat sheet on resolving some of the most frequent issues web scrapers face.
- Failed page downloads: Sometimes you’ll try to scrape a page, and the scraper won’t be able to load the page. There are a few reasons this might be the case. You may have run into a CAPTCHA, or the site may have blocked you. The easiest way to avoid both of these solutions is to slow down your scrapes. This avoids triggering security features that throw up hidden CAPTCHAs to suspicious users.
- Blocked IPs: If your IP address is blocked from accessing a site, the site will display a message like “The owner of this site has banned this IP address from visiting the site” instead of the standard page. If your scraper isn’t collecting the information you expect, visit the site with your scraper’s IP address to look for this message. If you’re blocked, implement rotating proxies to regain access.
- Asynchronous page loading: If a page uses AJAX calls to load content, a lot of data won’t be visible in the HTML when it first loads. If you’re not gathering as much information as you expect, you can use Selenium to force the site to perform more calls. Use the Key function to scroll the site and force an AJAX call. It should load more of the page and allow your scraper to gather more information.
- Page timeouts: CAPTCHAs can also lead to page timeouts. If your scraper is running into a lot of timeouts, it’s probably hitting invisible CAPTCHAs. This is another situation where slowing your scraping program and using proxies can help prevent the bot from getting detected.
- Failed redirects: A redirect sends a browser instance from one page to the next automatically. It takes time to follow a redirect, though, so if you scrape as soon as you hit the first URL, you won’t gather anything but a 3XX error. You can use Selenium to wait for the redirects to settle. Just use WebDriverWait() to add some time between inputting the page URL and actually gathering the information you care about. The redirects should finish in just a few seconds.
- Authentication requirements: Some sites require authentication beyond just a username and password. These sites require things like CSRF tokens as well. You can use the Python library BeautifulSoup to collect tokens when you’re logging in. A great way to capture tokens is to use Selenium to make an HTTP request, then use a line like this: token = soup.find(‘input’, {‘name’: ‘loginCsrfParam’}).get(‘value’). This captures the token, and you can neatly add it to your main program the same way you added the username and password.
- Bad HTML: Most web scrapers rely on well-patterned HTML to collect the data you care about. Unfortunately, some sites just don’t have great HTML. They may have been written by someone who didn’t understand HTML well, or they may use something called “dynamic server-side CSS,” which generates unpatterned HTML to generate dynamic and customizable sites. Either way, it’s a challenge to scrape. You can use XPath and regular expressions to get more specific results even from confusing HTML trees.
Start Using Selenium to Web Scrape the Right Way

Selenium may not be the best solution for web scraping on its own, but it’s an excellent tool to add to a Python-based scraper. By reaching the end of this guide, you’ve learned the pros and cons of Selenium web scraping, how to use Selenium to scrape data, and some expert-level tips for making a Selenium web scraping Python program even better.
If you’re excited to write a web scraper using Selenium, you’re almost ready. All you need is a collection of high-quality residential proxies to add to your scraping program. Don’t wait: get started today with safe and secure proxies from Rayobyte.
The information contained within this article, including information posted by official staff, guest-submitted material, message board postings, or other third-party material is presented solely for the purposes of education and furtherance of the knowledge of the reader. All trademarks used in this publication are hereby acknowledged as the property of their respective owners.