




















Selenium: Using Python to Find Elements via XPath
If you are using Selenium now for test automation, chances are good you are spending some time fletching elements. This can be done through various methods, but XPath is perhaps the best route for most people to use. Selenium for XPath for test automation offers both basic and advanced tactics to allow users to retrieve elements. At the same time, it is noted as one of the most versatile solutions available as well.
Let’s take a closer look at why all of this matters and how you can apply Python XPath solutions to the work you are doing. Selenium supports various programming languages, including Python. To help you see how you can use XPath in Selenium with Python to find elements, follow the insights here. Keep in mind that this may seem like a long project, but once you learn the process, it is both fast and easy to use Selenium by XPath to fetch elements.

Start at the Beginning: What Is XPath?

What is XPath in Selenium?
XML Path Language, nearly always referred to as XPath, is a syntax used to navigate through elements on the Document Object Model (DOM). XPath allows users to target nodes from your XML document – which means it is not restricted to HTML like others. What you will find is that XPath is very commonly used in web test automation because it is flexible and versatile when locating elements from a page.
Selenium by XPath with Python
With some insight into how Python XPath work, you will be able to use this tool to fetch a range of elements in a fast and efficient manner. To use these tools, you will need some experience with Python and Selenium (and that means using the most up to date version of Python on your system). You will also need to have Google Chrome browser installed using the Selenium bindings for Python.
To get started with this process, you must have a setup that works. To find out if you’re ready to go, open a project. Then, add the following to the main file:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get9’https://selenium.dev/”)
Now, to check it, your goal is to insert a main file name. For this example, we will use main.py, or python main.py as you would run it.
If you’ve done this properly, you should see a Chrome window open up and then go to the Selenium website. It should then automatically close. If something did not go right to this point, you need to go back and correct the concerns now before moving forward.
Utilizing XPath to Find a Specific Element with Selenium Python

The next process is to find a specific element using XPath.
The best way to do this is to test out a few different steps. For this process, we will use the Selenium website as a demonstration feature. Visit the Selenium website at https://www.selenium.dev/.
When you get there, you’ll find various targets you could use. For this process, we are going to use “projects” at the top of the page in the navigation menu. This is the “element” we are going to find using Selenium by XPath.
To get started, you need to have a good understanding of the website’s DOM. This will help you determine how to access the desired element.
Head back over to the Selenium website and right click on “Projects” on the navigational menu. From there, click “Inspect Element” from the list. This allows you to see the hierarchy of nodes for that site.
Take a close look at it, and you’ll see:
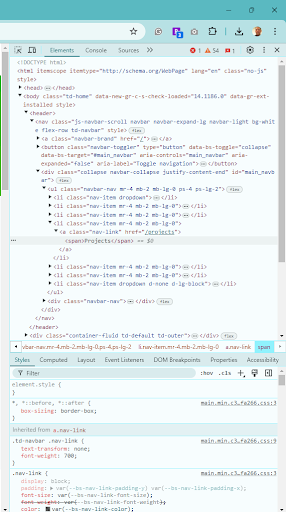
If you check this out, you’ll see “Projects” listed as the fifth element, which contains the <a> element. This should be a link. It will specifically point to the projects page on the site.
Now, with that information, we will be able to write a query to get the element. To do that, start with a query that starts from a root element or relative path. You should create a query that looks like this:
“./html/body/header/nav/div/ul/li[5]/a”
To understand what this means, consider the following:
- The ./ at the start shows that this is an absolute path
- All of the elements are then listed from the root until we get to the <a> that we desire
- The 5 in this sequence refers to the fifth item on the list (which is projects), and this captures the link inside of it.
With that information, try out your own location or continue with this one.
Use Python and Selenium to turn this query into a runnable tool. Here’s how to do this.
Add the following import:
from selenium.webdriver.common.by import By
The next step is to add the following to the bottom of the file:
target_element = browser.find_element(By.XPATH,
“./html/body/header/nav/div/ul/li[5]/a”)
print(target_element.text)
Take a closer look at the resulting information. The first line includes the find_element. This is what is used to find the node you want to target. It then includes two arguments:
- The method is to search the element using XPath
- The second argument is the path
After all of this, you have a print statement. If you have all of this in place, you can then run the code above. When you do, you should see “Projects” displayed on your console.
Pretty specific and simple, right?
How to Use This Method to Find a Specific Element Using Relative Path

The first step you completed was an absolute path to find an element. That is an option but not always ideal for scenarios. In many cases, the page may see a change, and that would lead to the path you used to no longer function. That means all of your automation work is no longer effective.
That’s why we incorporate relative paths. They are more versatile. You will write a relative to a given element, and it will intrinsically update or change the page structure.
The process of changing this to a relative path is rather simple. In the above example, you just need to modify the second argument created for the find_element task. Update it as the following:
“//nav/div/ul/li[5]/a”
This means there are now two slashes at the start. In this situation, it now starts from the nav element instead of the root element when compared.
In this situation, the query will continue to move through other nodes. If something within the tree changes, it does not change the query and does not require an update. However, if there is a change to the hierarchy, that will require an update to this process.
Selenium XPath and Functions

XPath Python for elements is rather common and something you should learn to do proficiently. However, there are other tasks that can also be completed using these tools. One of the more advanced but still very helpful skills to learn is how to use Selenium XPath Functions.
When you are writing your query, there are numerous functions you can use. Learning these and using them really will make the entire process easier when utilizing Python Selenium by XPath. The most important to learn include:
Contains()
Starts-with
Ends-with()
It’s pretty simplistic to see what these refer to, of course. In this process, the contains() function will include two arguments: the test() attribute (which will return the text from the element you searched) and the specific string you are looking for.
Why would you do this?
In short, this type of action tells Selenium to provide you with all the elements where the text contains the word you placed into the contains() field. With this method, the find_element method will return just the first match. You can also use the find_elements variation. In this situation, it will give you all of the matches to the query you have placed.
Another route to consider is the starts_with() function. You can easily see what this means. Try this query to see what it provides to you:
paragraph = browser.find_element(By.XPATH, “//p[starts-with(text(), ‘Why’)]”)
Change up the “why” to any word you want to check out. When you do, the following applies.
The text() attribute is used to retrieve the text from elements. The starts_with() function will bring you any strings that start with “why” in it.
Try another word to see how this plays out.
What you will find is that the entire process gives you a pretty straightforward method of finding the strings relevant to your project. You can test this numerous times and try out a variety of applications to fit your goals.
You can use a variety of different tools for Selenium XPath Python functionality. Here are some more locators you can use for finding a single element.
- Find_element_by_id: This will find the first element with the ID that you provide to it, returning the matching location to you.
- Find_element_by_name: As this name implies, you can use this method to find an element with the name attribute value that matches the location
- Find_element_by_xpath: This will find the first element that has the Xpath syntax matching the location that you provide within it.
- Find_element_by_link_text: You can use this to find the element with the specific link text value that you place into the line.
- Find_element_by_partial_link_text: This will provide you with the first element that has a partial link text value that matches the information you have inputted.
- Find_element_by_css_selector: You can use the tool to find an element with a matching CSS selector to be returned to you.
- Find_element_by_class_name: This will bring up the matching class attribute name returned to you.
There are others you can try out as well.
Why Use Python Selenium Find Element by XPath?

There are certainly many ways to use these tools, but why Selenium by XPath for your project? Let’s try to offer some specifics here.
Selenium’s Python Module is actually designed to automate testing within Python. That is Selenium Python bindings are a simple API to write various tests using the Selenium WebDriver.
The main reason so many use this tool is because you can find an element by Xpath Selenium Python with ease.
XPath is a language that can be used for locating nodes in your XML document, and to work Selenium lets users leverage this language to target elements within the web application. It is a simple method to use and allows you to locate key information rather quickly.
One of the main reasons for doing so is that you do not have a suitable ID or a name attribute for the element that you need to find. You can use the various fields above to find an ID or name attribute that fits your expectations and goals.
Selenium by XPath simply makes sense. It provides a way for you to locate the specific information you need quickly. You can use Selenium to find an element by Xpath Python within a matter of minutes and move your project forward in no time.
Using Selenium Python to find elements using XPath is a simple and effective resolution. If you need help with the process or proxy for better experience, we encourage you to take action and contact our team to learn more. Turn to Rayobyte for the support you need.
The information contained within this article, including information posted by official staff, guest-submitted material, message board postings, or other third-party material is presented solely for the purposes of education and furtherance of the knowledge of the reader. All trademarks used in this publication are hereby acknowledged as the property of their respective owners.



