The Ultimate Guide To Web Scraping With A PowerShell Tutorial
If you’re looking to grow your business, you’re probably already sold on the value of data. Good-quality data can keep you up to date on important business intel like:
- How your competitors are pricing their goods and services
- Broader trends in the economy and insights that can inform how you should strategize for the coming quarters and years.
- How your brand is perceived by your potential consumers (sentiment analysis)
Thanks to the billions of internet users online at any particular moment, data affords you a to-the-nanosecond picture of potential (and actual) consumers’ thoughts and intentions. While surveys have their place, what you really want is access to the candid, unfiltered things people think, as opposed to contrived answers people give surveys.
So how do you access those unfiltered thoughts and sentiments, not to mention data on your competitors’ strategies and the larger economic and industrial climates in which you operate? PowerShell is one tool that gives you outstanding access to data — so long as you know how to use it. If you’re new to web scraping with this program, follow this PowerShell tutorial.

The Importance of Web Scraping

Web scraping is an essential practice when it comes to understanding global affairs and feelings as they relate to your business.
Web scraping involves searching publicly available data like comments sections, forums and chats, and social media and “scraping” them to source mountains of data that, properly analyzed, gives you an accurate read of what’s on people’s minds. Are they mentioning your brand unprompted, for example, and if so, are they mentioning it in positive or negative terms? Bear in mind that web scraping involves publicly-available data given up freely by its users, but it can be invaluable to your business — if you know how to access and analyze it properly.
Scrape at Scale With Chromium
Playwright-compatible. Self-hosted. Built for real infrastructure.

The process of web scraping is typically automated because it relies on big data to work. More than 2.5 quintillion bytes of data are created daily, and the volume of data (from every web search, article, transaction, and app that tracks your movements, to name a few) keeps increasing.
It would be overwhelming for one person to gather sufficient data, particularly when you consider the important characteristics of big data:
- Volume: The sheer amount of data
- Velocity: The speed with which data is created, with up to the second data being most valuable for many business transactional and analytical purposes
- Variety: The multimedia ways in which data is processed and put out there
- Variability: Data often comes in fragments, which are incomplete and have to be matched with bigger patterns or other data sets
Web scraping is typically a two-pronged approach. The data is first gathered, then arranged and analyzed in a spreadsheet (or equivalent). Data collection can also be done in one step by looking for specific answers to your questions. But the two-pronged approach provides you with the wealth of data you’re looking for and allows you to find patterns you may have been unaware of.
If you were running a website that sold hotel bookings, for example, you might want to know the prices and specials your competitors were offering and what the most popular searches for destinations and packages were.
But you might also benefit from more abstract information like weird weather patterns or political instability in overseas countries that could impact future traveling plans. Surprising trends could emerge regarding specific demographics of travelers, which can be helpful as you craft your special offers and plan for the future. It may not be until you gather all the data that such patterns emerge.
Data scraping and automation
Given that you need reams of data to make web scraping worthwhile, automation is the only method that makes sense — using bots and software scripts to analyze (or parse) HTML pages. Parsing HTML refers to taking raw HTML code, breaking it down, and making a branching kind of tree diagram (a Document Object Model) that can be analyzed.
That means writing your own scripts and using common web languages and libraries to analyze the torrent of data gushing through web pages at any moment. That’s achievable — many companies have come to rely on it — but you should take it slowly and methodically when you start. Some things to bear in mind while you’re designing your data capture approach:
- Some websites have all their important data behind a CAPTCHA, so you will need to invest in a CAPTCHA breaker.
- Some websites have all their relevant information on one page, but others have several pages of data, requiring a scraper tool that “knows” to look at various pages.
- Hoovering up all the data will cost you in terms of storage and make analyzing it an ambitious task. You may want to keep your early searches concise and focused until you get the hang of web scraping and decide it’s worth boosting your storage and analysis capacities.
PowerShell vs. Other Computer Languages for Web Scraping

Many scrapers use Python for their scraping needs, and that’s understandable. Python is the world’s most popular computing language and presents the building blocks and means of analysis for most web pages. Python is a relatively straightforward, user-friendly language without any curlicues, which has obvious appeal. And since it’s open source, many bugs are fixable by its passionate community of worldwide users.
Python’s popularity is another point in its favor. The data contained in most web pages will be easily accessed via Python. It makes sense to go with a tool that’s as close as possible to being a skeleton key.
Java is another possible choice, but it is more complicated to use than Python, and its popularity is declining. Like Python, it has many premade libraries and scripts that allow you to collect data easily. Java works best (logically enough) on pages that use a lot of Java. But since these are in decline, many web scrapers have switched to Python.
However, it’s not always possible to use Python to scrape data, and there are other powerful and popular options you should consider. PowerShell is one that’s well worth your attention.
The Strengths of Scraping Data With PowerShell

Designed by Microsoft, PowerShell is “a cross-platform task automation solution made up of a command-line shell, a scripting language, and a configuration management framework.”
Part of the reason for PowerShell’s preeminence in web scraping is that it’s made by Microsoft and provides easy access to sites designed using Microsoft products. It’s also popular because it offers many functionalities and is relatively easy to master (you can learn as you go with the help of forums and user chats). And it allows for many functions to be performed in an automated fashion once you have written scripts or made use of existing PowerShell libraries.
Though PowerShell is a product created by Microsoft, it also runs on Linux and macOS, at least in its PowerShell core version.
How does PowerShell work?
In the words of DBpedia, a shell is a “computer program which exposes an operating system’s services to a human user or other programs.” Websites communicate with us, but also with one another. That’s what’s meant by an Application Programming Interface (API), which is what you’re accessing when you scrape data.
The shell represents the outer layer of the operating system, which is what you need to peer beneath to get to the content the website has encoded. PowerShell allows you to convert a webpage into objects which you can then easily scrape.
So instead of viewing a website as a mix of graphics, text, and video, a shell allows you to see it as lines of code written in HTML, the standard markup language for webpages.
Once you can see those lines of code, you can create different commands using a specific scripting language to search for the things you want to know.
PowerShell is a popular command shell for several reasons. It allows users to:
- Automate the management of systems
- Build and test solutions to bugs and issues with software and apps
- Manage enterprise infrastructure with configuration as code
And in our case, PowerShell can also generate scripts for web scraping. PowerShell may seem more complex than Python — or at least requires a bit more knowledge to work efficiently — but don’t be intimidated by it.
Once you get used to seeing websites spooled out in language and code, it’s not that hard to adjust — think of it like learning a language or math formula at school and how quickly you started to see things in this new way.
Pros and Cons of Scraping Data With PowerShell

Every tool has its pluses and minuses. Here are some of the pros and cons of using PowerShell:
Pros of web scraping with PowerShell
- It is a well-supported software designed by Microsoft, so it’s almost universally compatible with websites you want to scrape. Because it’s designed by Microsoft, it also supports .NET objects and forms.
- PowerShell is a relatively simple coding language to learn, designed to be competitive with Linux.
- It makes automation easy, which is important when you’re web scraping.
- PowerShell has a large community of users available to offer support and answer specific questions.
- The software is easily interactive, so you can fix coding problems as you go.
- PowerShell is now on version 7.2 and has had many bugs worked out.
- PowerShell is user-friendly and protects against accidental commands. For example, you have to right-click your script and select Run with PowerShell rather than just double-clicking.
Cons of web scraping with PowerShell
- PowerShell is not quite as simple as Python.
- The software has some security risks. It may leave loopholes open while IT professionals connect remotely to servers, so it may not be as secure as other web scraping methods.
- PowerShell comes in a few iterations that are still out there, and not every command that works in 5.0 will work for 7.2.
- It may require its own server, which can take up valuable computing space and energy.
A PowerShell Tutorial

This handy primer will help you learn some basic concepts and commands so you can get scraping with PowerShell.
Cmdlets: A basic building block
A cmdlet is a lightweight command that performs a specific function or several functions. Programming a cmdlet gets progressively more complex, depending on your desired functions. Running a cmdlet like Invoke-WebRequest is how you begin many important requests in PowerShell.
“Verb-noun” syntax
The beauty of PowerShell is that it was designed to be user-friendly and a Microsoft competitor to Linux, so the syntax of its commands follows a “Verb-Noun” pattern.
“Copy-Item” copies a file, for example (pretty easy, right?). If you’re worried about PowerShell understanding your verb command, you can run “Get-Verb” to see the list of verbs that PowerShell will understand. (If you use a command with an unapproved verb, you will find out as the Import-Module command will display a warning message until you land on a successful command). To narrow the focus, you could run Get-Verb un*, which would give you the list of supported verbs that start with -un (e.g., undo, unblock, unpublish, uninstall, unregister, unblock, unprotect).
Similarly, running the “Get-Command” function will give you an accepted list of commands.
Some of the verbs that work in the security group are:
- Block
- Grant
- Protect
- Revoke
- Unblock
- Unprotect (handy for removing safeguards from a resource once they are no longer needed)
So if you wanted to see use PowerShell to begin analyzing the site website.com, you would write the cmdlet:
Invoke-WebRequest’website.com’
This would then render the site into a block of text (or an object) with all its parts represented as code, including its URL, graphics, metadata, and any text that may have been entered into the chat portion of website.com.
As this command gives you everything on a platter, the next step is to narrow your search.
According to Microsoft, AllElements will give you a list of all the objects on web page. Following this:
- Type in Where and do a match on versionTableRow.
- Grab the InnerText property and pipe all of this to ConvertFrom-String using the contents of $t as the template to convert the text to objects with the property names Name, Version, Downloads, and PublishDate.
This should give you text that you could then put into a spreadsheet like Excel and then parse, doing searches for the elements you’re interested in examining.
You might add parameters like –Url or -images to filter what you’re looking for depending on what info you want to scrape. When you comb through the returned text objects, $WebResponse.Images will give you every HTML detail about the images on a website (dimensions, possibly description, and source).
Scrape at Scale With Chromium
Playwright-compatible. Self-hosted. Built for real infrastructure.
An alternative command to search content only
Typing in the cmdlet Invoke-RestMethod instead of Invoke-WebRequest will give you only content and no metadata (you could also type in the prompt Content).
Metadata (the data about the data) might be useful if you’re looking for such information as who’s coming to your website, the kinds of media competitors’ sites might be using, or the volume of sales that competitors’ sites are capable of, to cite three examples. Governments may track metadata, for example, to trace the contact list of persons of interest.
But you may be looking for more concrete data, such as sales prices, so you want to filter out things you don’t need, like metadata.
Additionally, you may have to translate the data you’re receiving. For example, it may have been encoded in JSON (a specific coding format that uses human-readable text to store and transmit information). In that case, you would have to translate it by running the cmdlet ConvertFrom-Json if using the Invoke-WebRequest approach. If you’re using Invoke-RestMethod, translation from JSON will be done for you automatically.
Once you have your data laid out, your task becomes about running more specific searches to break it down or filter out what you don’t need.
This involves using some set commands known as regular expressions or, in the case of many Microsoft products, .NET regular expressions. .NET is a Microsoft-created open-source developer platform used to both build and analyze websites and apps. .NET supports several languages and libraries and has a standard and consistent set of libraries you can use as basic shortcuts. PowerShell is based on its language and functionalities.
Regular expressions: Important commands for scraping data with PowerShell
Websites (or most structured communication) involve many predetermined forms. When you scan a webpage, you’re probably used to seeing elements such as:
- Email addresses and contact information
- Photos and captions
- Submission and personal information forms
Breaking a page’s data down rapidly means recognizing those structures so you can extract the data within.
“Regular expressions” provide a way to identify such patterns and allow you to do quick searches for specific character patterns and extract text substrings.
So you should take some time to familiarize yourself with these shortcuts. Here are a couple of examples of how they might help you:
- Input the command \$ to find dollar prices listed on a page, for example, if you were looking at a competitor’s prices.
- Type in website.links to enumerate various properties of the links this page connects to (this may be helpful if you’re looking at the affiliates and corporate connections a competitor has). If you only want the URLs of those links and not their content, type in the command $website.links | select href and so on. But the tool will also give you everything you can think to do with those link objects (inner HTML, outerHTML, etc.).
Finding an object on a page with PowerShell
Say you’re looking for a specific item on a sales site to track its availability or price.
Start by running the Invoke-WebRequest cmdlet, and then look for the specific element you’re searching for (for example, Hawaii trip prices). PowerShell runs well with Google Chrome, giving you access to its Developer Console.
Right-click over the item you’re looking for (the Hawaii trip price), and you should find it pop up in its parallel form as code.
Run $rep.ParsedHtml.body.getElementsByClassName(‘name-of-your-item’) to isolate it. You can then create a loop (see below) so that it keeps popping up, and you can compare its prices and trends at certain time intervals.
Creating a loop in PowerShell
Creating a loop allows you to run a command repeatedly and automatically when gathering data. The For Loop allows you to repeat a task numerous times, process collecting data, or specify objects you’re looking for. The For Loop is programmed to test how often a certain proposition is true (say that trip prices remain over $500) and ends when it deems the condition false.
To create one, use this syntax:
for (<Command>; <Conditional Test>; <Repeat>){
<Script Block>
}
The command block is where you write in the initial command or premise whose truth your loop is testing. In the conditional test block, your loop will evaluate the truth of your initial condition. This will repeat until the condition is deemed false (say, the price of the fare you’re tracking falls below $500).
As its name implies, the repeat block repeats the command or executes a couple of different ones, perhaps with modifications regarding the counting variable.
You can break the loop by hitting CTRL+C.
Further options for web scraping with PowerShell
As you get more comfortable with using PowerShell, your searches can get more ambitious. Similarly, once you see patterns within a page of content, you can refine your searches. One tip: keep the webpage open on one browser window while looking at the extracted code on another. You can start to see how they correlate as you parse the HTML. A caption, email address, headline, or form field may be categorized (or “tagged”) a certain way, between <>. Once you see that pattern, you can use the -match command to separate and filter all the same elements.
You can create commands to find the URLs for images, which could be helpful when combing through social media sites or other graphic-rich sites. This user forum has one suggestion for finding images from a Bing search.
If you want to program your web scraping search to use different proxies, you can. Using the Invoke-Webrequest cmdlet uses the proxy in your Windows settings by default.
You may want to use a different proxy (or several different proxies) to perform your web scraping tasks and make sure they are successful. You can override the proxy your default settings choose by using the -Proxy parameter. If your proxy has to be authenticated, you can specify it with the -ProxyCredential parameter.
Similarly, there are commands you can use to get around cookies (which track user behavior on the web) or at least be aware of them. If you search for $cookie, you can look out for specific cookies on pages you’re combing, then refine it by cookie subtype.
It’s all quite intuitive if you think about the components of a web page. So if you want to search for forms, search for Forms or InputFields, which will give you a readout of the website’s forms and autofill regions.
The cmdlet –UseBasicParsing will save you time searching since it breaks a website down to its core components and then rapidly trawls through them. You can even scrape your own site using the Invoke-WebRequest cmdlet to see if there are any broken links, cookies you don’t want, or expired data to fix.
So that’s a handy beginner’s PowerShell guide. Armed with these basic commands, you can create your own script to scrape the data you want using PowerShell.
It only takes a little practice to get the hang of it.
Use Proxies To Support PowerShell Web Scraping

PowerShell is a user-friendly tool that can automate your web scraping ventures, and the above steps are enough to start you on a turbocharged search for web data that can help your business.
However, one obstacle to web scraping is that many websites have security functions set up to block requests that seem to be automated and from bots — like your scraper. These security systems predict human behavior (the number of times a person might typically linger on a site, the kinds of things they will look for, the interactions they may have, and the volume of requests they would normally make, not to mention the time of day). When they believe they are being bombarded with numerous requests in a short time, they may block you entirely or use some other security measure to “spoof” you, that is, derail your request. Common tactics include rerouting your request to a blank page, yielding zero usable data. You may be familiar with the “are you a robot?” CAPTCHA quizzes that ask you to click all the pictures that feature red traffic lights or similar objects. These are the most straightforward filters aimed at preventing bots from accessing important info.
Overcoming obstacles to web scraping
Using proxies is the only way to get around the digital gatekeepers standing between you and the data you want to access.
Proxies are middlemen between your request and the server you are targeting. They allow for a degree of anonymity that stops the target server from identifying your IP address, which gives it a fairly specific sense of where you’re making your request from and can be used to determine if you’re a person or a bot.
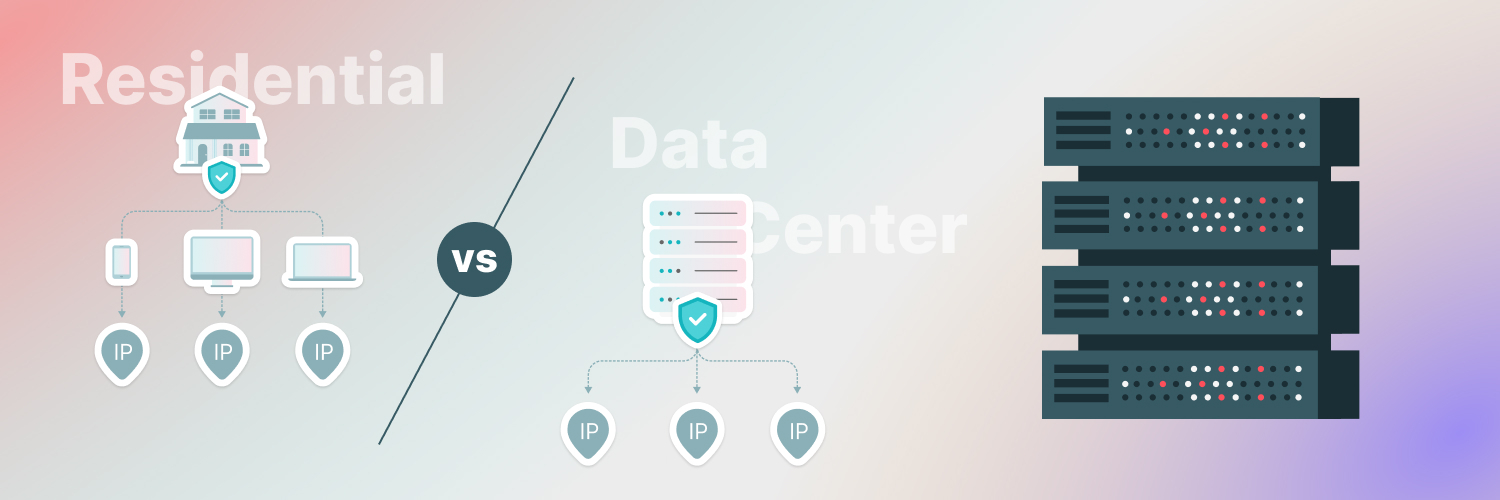
There are two main types of proxies: residential and data center. Residential proxies (which must be acquired with the full consent and preferably compensation of their owners, a code of ethics that Rayobyte scrupulously adheres to) use domestic IP addresses on loan from homeowners who aren’t using all of their bandwidth. These can be a little slower, as you are sharing bandwidth with a domestic user, and also a bit more expensive as they are owned by individuals. But they provide the best cover to bots, as they are attached to “real” IP addresses, and bots cannot afford to block genuine internet users from accessing their content.
Data center proxies are set up like call centers with hundreds or thousands of IP addresses dedicated to providing proxies for internet users trying to gain access to data. With more options and less overhead, these proxies can be cheaper. They can also be easier to block since more sophisticated security programs are more likely to detect the equivalent of call centers furiously making robocalls.
There are other ways of categorizing proxies: rotating and fixed. Fixed proxies use one IP address, whereas rotating proxies constantly change addresses so that if one is blocked, you (or your automated script) can rapidly switch to another. Data moves so quickly on the internet that it can cost you valuable information and money to have your connection severed due to a blocked request or IP ban. Competitors’ prices, for instance, may oscillate from second to second, and missing this data could make your offerings look weaker by comparison.
Rotating proxies are a great way to maintain the anonymity and privacy of your searches. Proxy requests can come from servers worldwide, creating a randomized pattern of requests that’s nearly impossible to detect or break. And Rayobyte also offers intelligent scripts that detect whether you have truly been blocked or if it’s just a technical difficulty.
Rotating proxies can be slightly more expensive, given the increased firepower involved — and that’s a good thing. Unscrupulous rotating residential proxy sellers will try and squat unannounced on residential IP addresses. That’s essentially stealing. Paying more for rotating residential proxies means you’re compensating individuals for using their property, which is the only way to go. When done ethically, rotating residential proxies represent the most intelligent way forward for data scrapers.
The need for security and reliability means you need proxies to run your PowerShell-scripted automated searches. Rotating residential proxies provide the peace of mind and security you need to capture and analyze data without interruption or fear of being blocked.
Finding reliable proxies for web scraping
When it comes to buying proxies, you need to rely on the expertise, buying power, and ethical code of a trusted provider like Rayobyte. Some choose to go with free or shared proxies. But here’s why you shouldn’t:
- Free proxies have low bandwidth since you’re sharing them with (many, many) other users.
- Free proxies are easily hacked, making your data visible during transport or — worse — used as a Trojan horse to install malware on your computer or steal your data.
- Someone you’re sharing the free proxy’s IP address with could quite easily be banned for bad behavior. Since you have the same IP address, you could get banned, too.
It’s not worth the risk. But not every proxy seller is created equal, either.
Unlike some proxy sellers, Rayobyte ensures their residential proxies come from IP address owners who give explicit consent to the use of their proxies — upfront, in plain language, and regularly and explicitly renewed. They are also compensated for the usage of their IP addresses. On occasion, Rayobyte partners with other providers, but only if they also uphold Rayboyte’s strict code of conduct.
Rayobyte’s access to proxies worldwide also helps create a pattern of requests to servers that can’t be easily construed as bots. That means you get unimpeded access to the data you’re scraping, which is crucial when building an accurate picture of your operating environment. It also helps maintain your privacy, putting up an effective wall between you and anyone trying to track you online.
If for whatever reason, one proxy gets blocked, Rayobyte’s automated technology switches you immediately to another, so you can go on performing your PowerShell web scraping in peace.
Proxy Pilot: The perfect companion for web scraping
Whether you use a prebuilt scraper or write your own PowerShell script, you should consider using Rayobyte’s Proxy Pilot, which automatically smoothes out many of the potential bumps in the road to web scraping. Proxy Pilot manages the moment-to-moment tasks of rotating proxies, such as:
- Switching immediately to a different IP address when one proxy is blocked
- Determining whether your request has truly been blocked or is just a technical error, in which case it sends a retry request
- Keeping track of necessary cooldown times before making another request
You’ll have all the functionality you need to power a sophisticated and transformative web scraping practice. If a request has failed, Proxy Pilot will tell you why. It will also tell you:
- How much bandwidth you’re consuming
- How long it takes for your requests to be fulfilled
- Your overall success and failure rates
- A complete list of the domains your requests are connecting to, so you can make sure you’re on top of your goal
Proxy Pilot also supports geo-targeting, so it’s easy to do A/B testing on proxies in two countries if needed. It offers the most data-driven approach to collecting data and makes for the fastest and most efficient process possible.
And you can use Proxy Pilot by adding a few lines of code to your scraping software. It’s free, open source, and helps make monitoring your automated web scraping easy.
Automation with Rayobyte
Rayobyte also has a powerful automation tool for web scraping: Rayobyte’s Web Scraping API. If you don’t have the bandwidth to learn a new scraping language or keep up with your scraper, automation is the name of the game. Rayobyte’s Web Scraping API is priced competitively, with no monthly costs or hidden fees. If you know how big the scope is of your data-collection project, Rayobyte’s Web Scraping API can help you find the most affordable option — if you don’t feel confident in your PowerShell or other coding abilities.
Using PowerShell and Rayobyte To Harness the Power of Web Scraping

There’s more than one way to scrape the web. You can write your own script using this PowerShell tutorial, or you could use Rayobyte’s Rayobyte’s Web Scraping API, which offers you excellent analytics, speed, and affordability when you attack the world of big data. However you proceed, you shouldn’t go it alone. If you write your own script and use PowerShell, you should still use Proxy Pilot, a suite of tools that lets you see exactly how well your mission is progressing.
And you should certainly invest in the best residential rotating proxies, which make your process reliable and hassle-free. Data is important, but bad or incomplete data can actually set you back. If you’re determined to give your business the edge over competitors, you need to include web scraping in your arsenal, which means doing it right.
Call Rayobyte today and talk to one of their experts to help you craft the best web scraping practice you can! You’ll find that Rayobyte is the ultimate guide to web scraping.
Scrape at Scale With Chromium
Playwright-compatible. Self-hosted. Built for real infrastructure.
The information contained within this article, including information posted by official staff, guest-submitted material, message board postings, or other third-party material is presented solely for the purposes of education and furtherance of the knowledge of the reader. All trademarks used in this publication are hereby acknowledged as the property of their respective owners.