




















Working With XML in Python: A Guide to Python XML Parsers
As a Python developer, you’ll likely need to find a way to parse an Extensible Markup Language (XML) document. They’ve been a cornerstone of exchanging data between systems for years. Python’s rich ecosystem of tools and libraries offers a lot of support for XML manipulation.
This guide explores XML and the different options for creating XML with Python and navigating the document. Ultimately, you’ll better understand how to work with different XML parsers from the Python Standard Library and where you can tap into third-party libraries.
Need Data? Need Proxies!
Before you can start scraping and parsing, you need powerful, reliable proxies to keep you safe and successful.

What Is XML?

An XML is a structured data format containing tags defining elements and how they relate to one another within the document. Elements typically have attributes along with additional text and other details. One of the benefits of using XML is they’re readable to both machines and humans. It’s why they’ve become a popular way to set up structured information for different contexts like:
- Web Services
- Configuration files
- Data interchange
XML is best suited for storing and transporting small to medium data stores. One of the great things about Python, and programming in general, is that there’s always more than one way to accomplish a task. All the options explored in this road map let you create an XML with Python and store it in memory for parsing.
Parsing an XML Document

Below is a simple example of an XML document. It represents an online record store with two albums. Each album entry contains the following elements:
- <title>
- <artist>
- <price>
XML example
<recordstore>
<record>
<title>Spring is Here</title>
<artist>John Doe</author>
<price>15.99</price>
</record>
<record>
<title>Fun Times in San Diego</title>
<author>Jane Smith</author>
<price>19.99</price>
</record>
</recordstore>
The hierarchal nature of the XML data format allows you to represent it as a tree, as in the example below.
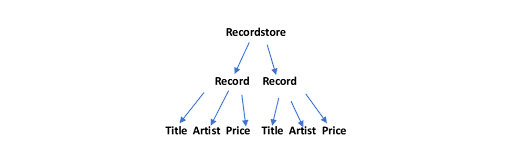
This understanding is essential to using different functions available to create XML with Python.
Document Object Model
Below is an overview of how the DOM works.
- Load XML document: After you find a way to create an XML with Python, load the document into memory using a DOM parser.
- Navigate the XML document: Once you’ve loaded the XML, start navigating through the structure using the nodes. Common methods used include “getElementsByTagName” and “childNodes.”
- Access elements and attributes: You can access the content of elements and attributes using different DOM methods and properties.
- Manipulate the XML document: Add, remove, or modify elements and attributes within the DOM.
The DOM should be familiar to anyone who’s worked with web pages. Web browsers expose the DOM, which allows developers to manipulate HTML markup using languages like JavaScript. HTML and XML are both markup languages, which makes it possible to parse the DOM.
The structure of the DOM makes it the most straightforward and versatile way to work with markup code after creating an XML with Python. Standard operations allow you to move from one element to the next and change various objects. Keep in mind that the DOM gets parsed as a whole. Therefore, you must consider its size and ability to fit into available memory. That makes the DOM best suited for relatively large configuration files versus huge gigabyte XML databases.
DOM parsers are best for situations where memory and processing time are less important than convenience. For example, you may need to set up and parse a small XML file. In that case, creating an XML with Python and using a module from the language’s XML parser library is more effortless.
If time is a factor, there are more efficient options available. After creating an XML with Python, you can try more efficient methods of parsing XML documents.
Simple API for XML (SAX)

Simple API for XML, or SAX, is an event-driven approach to parsing XML. Java developers created the library as an alternative to the DOM. Instead of loading the entire document into memory after creating an XML with Python, SAX provides a more scalable way to work with and manipulate large documents.
It reads documents sequentially and generates events after encountering elements, text, or attributes. You can handle these events through a user-defined callback function, which makes SAX more customizable than working with the DOM.
How SAX works
Below is an overview of how SAX handles XML files:
- Initialization: After creating an XML with Python, you must set up and configure the SAX parser. Developers have control over defining callback functions for specific events like finding the start of an element or locating text content.
- Parsing: The SAX parser reads the entire XML document and generates events for occurrences of every element, attribute, and event.
- Event handling: When SAX encounters certain events, it invokes the specified user callback functions that access and process data.
- Completion: After completing the XML parsing, SAX is closed or disposed of while the application continues with data processing.
SAX processes elements in the XML document from top to bottom. The push parsing approach by SAX generates callbacks to handle specific XML nodes. You can also dispose of unnecessary elements, allowing SAX to leave a smaller memory footprint vs. DOM. Another benefit to using SAX is its ability to handle large files, which is helpful when performing functions like indexing or converting an XML to other formats.
Benefits of SAX
Here’s what you gain as a developer with SAX after you create an XML with Python.
- Memory efficient: There’s no need to load the entire XML into memory.
- Event-driven: SAX lets you work with specific parts of XML when they are encountered.
- Customizable: You can customize the parsing process by handling events through user-defined callback functions and logic.
- Streamable: As a streaming parser, SAX lets you process XML documents of any size without worrying about memory constraints.
- Speedier: Because there’s no need for an in-memory representation of an AXM document, SAX runs faster than DOM-based parsers.
One drawback to using SAX is the need to perform multiple passes on a file after creating an XML using Python. Every node gets tracked, making the process more cumbersome. It’s also harder for SAX to manage deeply nested elements. You can only perform read-only parsing with SAX.
While SAX is a great space and time saver, it has a steeper learning curve than DOM. However, it’s an excellent tool for creating an XML with Python and working with it in real time.
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, compatible with all automation frameworks.
Using SAX with Python
Python provides developers with a SAX parser within its standard library within the “xml.sax” module. Below is an example of using SAX with Python after creating an XML document.
1. Define handler
import xml. sax class DocHandler(xml.sax.ContentHandler): def firstElement(self, name, attribs): # Handles the start of an element pass def lastElement(self, name): # Handles the end of an element pass def textContent(self, content): # Handle text content Pass
2. Create SAX parser
After creating an XML with Python, build an XML parser using the “xml.sax.make.parser()” function. Set your custom handler for the parser.
saxParser = xml.sax.make_parser() # Set the custom handler saxHandler = NewHandler() parser.setXMLContentHandler(saxHandler)
3. Parse XML document
Use the SAX parser to parse your XML document. Set the source as the place you saved your file after creating an XML with Python. In addition to a file, you can point to a string or network stream.
with open(“sample.xml”, “r”) as new_xml_file:
parser.parse(new_xml_file)
3. Handle events
As the parser moves through the XML document, it handles events by calling methods from your custom handler class.
class DocHandler(xml.sax.ContentHandler): def firstElement(self, name, attribs): if name == "elementName": # Access and process element attributes (attribs) pass def lastElement(self, name): if name == "elementName": # Handle the end of the specified element pass def characters(self, content): # Handle text content pass
Streaming API for XML

While not as popular as SAX, StAX is another option for working with a document after creating an XML with Python. It was built as an alternative to the heaviness of the DOM. StAX also addresses SAX’s lack of ability to navigate backward through a document. Like SAX, StAX started as a Java-based API. Its success led to the creation of similar modules in other languages, including Python.
StAX allows you to read and write XML via streaming. That lets programmers efficiently process documents after creating an XML using Python and avoids the need to hold the contents in memory. StAX also allows for more convenient state management, which refers to holding onto information about an application’s stored inputs like variables or constants. Stream events are consumed when enabled, allowing for lazy evaluation, meaning StAX only calls a value when needed.
How StAX works
Streaming is key to how StAX functions. It doesn’t generate events like SAX. Instead, StAX processes documents in increments. After creating an XML with Python, you can read and write XML data as it’s encountered. It fits various needs, including parsing documents and creating an XML document in Python of any size.
Below is an overview of how StAX handles XML files:
- Initialization: After creating the StAX parser or writer, you configure the code to fit your requirements.
- Iterative processing: After creating an XML with Python, you can navigate the document sequentially without holding onto the file contents in memory.
- Event-driven handling: StAX comes with an event-driven model that allows developers to handle elements, attributes, and content as they come up.
- Forward and backward navigation: StAX parsers typically use methods allowing you to move back and forth within an XML document, making it versatile enough to cover various use cases.
Parsing an XML file with Python xml.etree.ElementTree to emulate StAX
You can leverage StAX capabilities using the “xml.etree.ElementTree” module from the Python Standard Library. Keep in mind that it’s not a true StAX representation. However, you can use streaming to parse and create XML with Python.
1. Import xml.etree.ElementTree
Add the import statement to bring in the module.
import xml.etree.ElementTree as ET
2. Create the parser
Below is an example of code designed to set up an element tree for parsing an XML file.
# Create an ElementTree object from parsing an XML file
XTree = ET.parse("example.xml")
# Find the root element of the XML document
root = xTree.getroot()
3. Iterate through each element
Write code allowing you to move through each XML element and access the information they hold.
for xElement in root:
print(f"Element Name: xElement.tag}")
print(f"Element Text: {xElement.text}")
4. Access relevant attributes
Set up a code block for moving through the attributes of each XML file element.
for xElement in root:
attribute_value = xElement.get("attribute_name")
print(f"Attribute Value: {attribute_value}")
Creating an XML with Python
You can also create an XML with Python using the StAX capabilities in xml.etree.ElementTree. Use the following code example as a guide.
# Create a new ElementTree with a root element
root = ElTree.Element("root_element")
# Add any needed child elements
childElem1 = ElTree.SubElement(root, "child_element_1")
childElem2 = ElTree.SubElement(root, "child_element_2")
# Set the text content and related attributes
childElem1.text = "Text content for child element 1"
childElem2.set("attribute_name", "Attribute value for child element 2")
# Create an ElementTree from the root element
xTree = ElTree.ElementTree(root)
# Save the XML to a file
xTree.write("new_xml_file.xml")
Exploring XML Parsers in the Python Standard Library

Python provides built-in XML parsers in almost every Python distribution. Let’s look at some available parsers from the Python standard library that you can use after creating an XML with Python.
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, compatible with all automation frameworks.
xml.dom.minidom
The xml.dom.minidom represents a subset of standard DOM functionality, which allows you to use it for most XML-related tasks. It takes the DOM approach to parsing, meaning it holds XML contents in a treelike memory structure, letting you manipulate contents within the document.
Below is an overview of working with xml.dom.minidom after creating an XML file.
1. Import the module
Start by importing the xml.com.minidom module.
import xml.dom.minidom
2. Load and parse the XML file
Use the parseString method to parse XML from a string. The parse method is available for working directly with an XML file. You can find an example below using the Record Store XML file created earlier.
# Add a definition of the XML string xml_string = """ <recordstore> <record> <title>Spring is Here</title> <artist>John Doe</author> <price>15.99</price> </record> <record> <title>Fun Times in San Diego</title> <author>Jane Smith</author> <price>19.99</price> </record> </recordstore> # Parse the XML string dom = xml.dom.minidom.parseString(xml_string)
3. Work with XML elements and attributes
After parsing the XML file, you can work with any content. You can traverse the DOM tree and locate specific elements and related attributes.
# Locate and access the root element
root = dom.documentElement
print("Root Element:", root.tagName)
# Access specific elements and their content
records = root.getElementsByTagName("record")
for record in records:
title = record.getElementsByTagName("title")[0].firstChild.nodeValue
artist = record.getElementsByTagName("record")[0].firstChild.nodeValue
price = record.getElementsByTagName("price")[0].firstChild.nodeValue
print(f"Title: {title}, Author: {artist}, Price: {price}")
The above example accesses the XML document’s root element with “dom.documentElement.” Next, “getElementByTagName” looks for specific elements and navigates the DOM to find the text content they contain.
4. Modify the XML document
You can also change and manipulate the XML document, similar to how you do when creating an XML with Python. Here’s an example of adding a new record to the XML file.
# Create a new record element
new_record = dom.createElement("record")
# Create child elements for the new record
new_title = dom.createElement("title")
new_title.appendChild(dom.createTextNode("Music for Programmers"))
new_artist = dom.createElement("artist")
new_artist.appendChild(dom.createTextNode("Giles Freeman"))
new_price = dom.createElement("price")
new_price.appendChild(dom.createTextNode("18.99"))
# Append the child elements to the new book element
new_record.appendChild(new_title)
new_record.appendChild(new_artist)
new_record.appendChild(new_price)
# Append the new record element to the root element
root.appendChild(new_record)
5. Serilialize the XML
Once you finish working with the XML document, you can serialize it back to a string by calling the “toxm # Serialize the modified document to a string
modified_xml_string = dom.toxml() print(modified_xml_string) l()” function.
xml.sax

You can work with SAX and Python using the parse() and parseString functions by importing the “xml.sax” package. One difference between “xml.sax” and “dom.documentElement” is that you must provide at least one argument representing a content handler instance. This is similar to Java in that you subclass a specific base class.
1. Import xml.sax
Start by importing the xml.sax package.
import xml.sax
2. Set up a custom SAX handler
You’ll need to create a custom SAX handler to process XML data. You do that by subclassing the “xml.sax.ContentHandler” class. It then overrides any methods corresponding to the events you wish to handle.
class MySaxHandler(xml.sax.ContentHandler): def startSaxElement(self, name, attrib): # Handle the start of an element pass def endSaxElement(self, name): # Handle the end of an element pass def characters(self, content): # Handle text content Pass
3. Create the XML parser
Use the “xml.sax.make_parser()” function to create a SAX parser. From there, set your custom handler as the parser’s content handler.
# Create a SAX parser parser = xml.sax.make_parser() # Set the custom handler handler = MySaxHandler() parser.setSaxContentHandler(handler)
4. Parse the XML document
Use the parser to work with the file after creating an XML with Python.
# Parse the XML file
with open("sample.xml", "r") as new_xml_file:
parser.parse(new_xml_file)
Handle the Events
You can call methods from your custom handler class to handle events while parsing the XML document.
class MySaxHandler(xml.sax.ContentHandler):
def firstElement(self, name, attribs):
if name == "element_name":
# Access and process element attributes (attribs)
pass
def lastElement(self, name):
if name == "element_name":
# Handle the end of the specified element
pass
def characters(self, content):
# Handle text content
Pass
xml.etree.ElementTree
This Python module allows you to parse and manage XML documents. It’s also handy when you need to create an XML with Python. It implements an XML API that uses the ElementTree API. You work with XML with a tree structure, similar to a DOM.
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, compatible with all automation frameworks.
One of the benefits of using “xml.etree.ElementTree” is that it’s simple to use and doesn’t require extensive knowledge about parsing XML. Below is an overview of how to use the module to work with XML files.
1. Add the module
Import the “xml.etree.ElementTree” module.
import xml.etree.ElementTree as ET
2. Build an ElementTree
Use the ElementTree class to create an “ElementTree” object.
# Parse an XML file elemTree = ET.ElementTree(file=sample.xml') # Get the root element of the XML document root = elemTree.getroot()
3. Access elements and attributes
After parsing the XML document, you access the elements, attributes, and contents. The “xml.etree.ElementTree” module represents elements as objects. You can use methods to access the data, as shown in the example below.
# Access the root element
print("Root Element:", root.tag)
# Access specific elements and their content
for record in root.findall(record):
title = record.find('title').text
artist = record.find(artist).text
price = record.find('price').text
print(f"Title: {title}, Author: {artist}, Price: {price}")
In the above example, the find method lets you locate specific elements within the XML tree and access the content.
4. Modify and manipulate the XML file
Below is an example of using “xml.etree.ElementTree” to add a new record element to the XML.
# Create a new book element
new_book = ET.Element("book")
# Create child elements for the new book
new_title = ET.SubElement(new_record, "title")
new_title.text = "Music for Programmers"
new_artist = ET.SubElement(new_record, "artist")
new_artist.text = "Giles Freeman"
new_price = ET.SubElement(new_book, "price")
new_price.text = "19.99"
# Append the new record element to the root element
root.append(new_record)
5. Serialize the XML document
Once you’re done modifying the XML, you can serialize it back to a string or write the file changes using the “ElementTree” class.
# Serialize the modified document to a string
modified_xml_string = ET.tostring(root)
# Save the modified document to a file
with open('modified.xml', 'wb') as xml_file:
tree.write(xml_file)
Third-Party XML Parser Libraries
While Python has some robust parsers for creating an XML with Python and manipulating the data, you might want a parser with different capabilities. For example, you may need to validate the XML against a specific schema or work with more complicated XPath expressions. External libraries on PyPI allow you to do all that and more. Below are some you can explore.
- untangle: Provides a way to use one line of code to turn an XML document into a Python object.
- xmltodict: Lets you parse an XML and represent it as a Python library.
- lxml: This Python binding library is compatible with the Element Tree API. You can work with those capabilities and reuse your existing code by replacing the import statement.
Learn To Work With XML Files for Effective Web Scraping

Understanding how to work with XML on websites and other resources is essential for successful data collection. Creating XML with Python becomes much easier once you’re familiar with the ins and outs of XML. If you’re using Python to scrape websites, you also need to know how to use parsers capable of parsing XML. The right parser can make web scraping much easier and more convenient.
If you want to learn how to improve your web collection results, contact Rayobyte for a demonstration of our web scraping and proxy solutions.
Need Data? Need Proxies!
Before you can start scraping and parsing, you need powerful, reliable proxies to keep you safe and successful.
The information contained within this article, including information posted by official staff, guest-submitted material, message board postings, or other third-party material is presented solely for the purposes of education and furtherance of the knowledge of the reader. All trademarks used in this publication are hereby acknowledged as the property of their respective owners.



