The Complete Guide To C# Web Scraping With Proxies
In the data age, automation is king; a web scraper bot can scrape through web pages exponentially faster than a human copying and pasting data. That’s precisely why web scraping is one of the most popular data extraction techniques these days.
That said, there’s a significant downside to web scraping that even the most experienced scrapers may suffer from: proxy downtimes and IP bans.
It’s not all bad news, however. There are several ways around downtimes and bans. One of the solutions is to use a C# web scraper with rotating proxies.
This article will walk you through all the steps of making a C# web crawler from scratch. Hopefully, by the time you’re done, you’ll be convinced that C# is not a dying programming language like some claim, but a powerful tool for building web scrapers.
Keep reading to find out all you need to know about C# web scraping.

What Is C#?

Before we jump right into building a C# web scraper, it first helps to know a little about C#.
According to Microsoft’s official description, “C# (pronounced “See Sharp”) is a modern, object-oriented, and type-safe programming language.” With C#, developers can build several applications in the .NET architecture.
C# also has several other valuable features. It is a multi-paradigm language, which means it supports more than one programming paradigm. It is also a component-oriented language, a feature that lends well to creating and using software components.
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, Playwright-compatible.

What is the .NET architecture?
.NET is a development architecture and framework by Microsoft. It is cross-platform, free, and open source. For these reasons, the .NET architecture is well-suited for developing several types of applications.
In the context of C#, .NET is the Common Language Runtime (CLR) of C#. C# runs on both .NET and C# class libraries. CLR is Microsoft’s instance of the Common Language Infrastructure (CLI), which helps languages and libraries run together smoothly.
Advantages of C# and .NET
On its own, C# is a versatile programming language. However, when combined with the .NET architecture, it becomes a powerful tool that can benefit beginner and intermediate programmers alike.
One of the most significant advantages of C# is that it’s a multi-paradigm programming language. Rather than restrict themselves to a single paradigm, C# programmers can choose the paradigm best suited for their current task. This may include structured, imperative, object-oriented, or even functional programming.
C# also has some features that are well-suited for creating durable applications. These include Nullable types, exception handling, and lambda expressions, just to name a few. C# also supports asynchronous operations, which help in building distributed computing systems and applications.
However, the major advantage of C# when used with .NET is language interoperability. Language interoperability refers to how compatible code is with other programming languages. This compatibility is due to the Intermediate Language (IL) that the C# compiler generates is compliant with the Common Type Specification (CTS).
All in all, there are about 20 or so CTS compliant languages that C# can run with. These languages include the .NET editions of C++. F#, and Visual Basic, to name a few. C# code can interact with code written in these other languages as if all the code was written in the same language.
Why Use C#?

So far, you may have read the different features and advantages C# has to offer yet still be unconvinced. After all, you may be wondering: Why should I use C#? Isn’t a language like Python much simpler to use for web scraping?
While it is true that Python may be more beginner-friendly than C#, there are several reasons why C# may be a better programming language for building a web scraper. Here is how C# compares to some of the more popular programming languages for web scraping:
C# vs. Python vs. Java
Python pros:
- Dynamically typed language (can declare variables quicker)
- Easy to learn for beginners
- More user-friendly
- Open-source library support
- Line-by-line code execution
Python cons:
- Slower performance than C#
- Not memory efficient — more vulnerable to memory leaks
- Weak for client-side or mobile applications
- Possible runtime errors
Java pros:
- Supports multi-threading
- Platform-independent programming language
- Fast programming language
- Detailed documentation available
- Extensive third-party library support
Java cons:
- Not open-source — libraries can get expensive
- Heavily resource-intensive
- Just In Time (JIT) compilation is relatively slower
- Does not support low-level programming constructs (i.e., pointers)
- No control over garbage collection
C# pros:
- Fast programming language
- .NET framework and library support
- High interoperability with other programming languages
- Automatic memory management
C# cons:
- Statically typed programming language
- Steeper learning curve than Python
- More resource-intensive on the computer (Microsoft Visual Studio)
- Server running the application must be Windows-based (.NET framework)
Overall, Python is the most beginner-friendly language, followed by Java and C#. Static typing makes Java a bit more challenging to learn than the dynamically typed Python.
Still, C# is the fastest programming language among these three, followed by Java, then Python. Despite being more complicated to work with than Python and a bit more resource-intensive than Java, C# is still a reasonable choice for building a web scraper app.
Web Scraping 101: How to Scrape a Website With C#

You’ve now learned that C# is a reliable language for building a web scraper. Now, it’s time to learn how to make a web scraper in C#.
However, before jumping right into the coding, it helps to know a few preliminaries that will help you with web scraping.
First, you should know what your goal is when web scraping. Ask yourself: Do I want to collect contact information of potential customers or just know product names? You should have decided what kind of information you want to collect before writing a single line of code.
Secondly, consider whether you’re scraping static or dynamic web pages. If the web pages you want to scrape are primarily static, you can get by with a C# HTML parser. On the other hand, if the web page is dynamic, you’ll need to configure your C# web scraper to parse JavaScript code.
Finally, thoroughly inspect the website you want to scrape and analyze it. Your best bet is to run the website in the same browser you’ll be scraping it in. Turn on your browser’s dev tools and browse through the code to understand the website’s structure.
If you follow these preliminaries, you’ll have a much simpler time coding your C# parser and C# web scraper later on.
How to Make a Web Scraper in C#

Now that we’ve covered our preliminaries, here is a step-by-step guide to making a web scraper in C#. To make it easy to navigate, we’ve split the application into three parts.
Part I deals with setting up a new project and installing C# web scraping libraries. Part II is about coding the C# HTML parser and putting it all together to test the code.
If it’s your first time building a project in C#, you can start with Part I below. Otherwise, you can skip directly to Part II if you already have HtmlAgilityPack installed.
For our example, we have selected Coin Gecko, a cryptocurrency website that tracks different crypto coin prices and trends. You can scrape a different website here if you wish.
Part I: Setting up a new project
Step # 1
Launch Microsoft Visual Studio. If you don’t already have Visual Studio installed, you can download it for free from here.
Step # 2
On the Visual Studio home page, click the Create a new project option.
Step # 3
Visual Studio will present you with a list of applications that you can choose from. Look for Windows Forms App (.NET Framework) and click Next. If you’re having trouble finding this option, use the search bar on the top.
Step # 4
Give a name to your project; We’ll call ours “web_scraper.” You can optionally change the location for your project build from under the Location drop-down menu. You can also select the “Place solution and project in the same directory” checkbox.
Step # 5
On the Additional Information screen, select the Target Framework. For this project, we’ll use .NET Framework 4.7.2. Click Create once you’re done to finish setting up your new project.
Step # 6
Now, you’ll have to download an additional package for parsing raw HTML. Go to Tools > NuGet Package Manager > Manage NuGet Packages for Solution. Click on Browse and search for HtmlAgilityPack, then install the package.
You’re done setting up your project and installing all the relevant dependencies. Now all you have to do is add the relevant libraries in the namespace and start coding!
Part II: Coding the C# parser for web scraping
Step # 1
Once you finish setting up the project, you should see a Form1.cs file in the solution explorer. This form has the design of the application screen we’re working on. For now, you don’t need to add any buttons or boxes to the form.
Step # 2
Double-click on Form1.cs in the solution explorer, and it will bring up the Form1.cs [Design] tab in the main window. Again, double-click anywhere on the form in Form1.cs [Design] or press the F7 key. This step will take you to the Form1.cs C# code window.
Alternatively, you can navigate to Form1.cs by clicking on the drop-down menu on the left of the settings icon and selecting it. The settings icon is located to the left of the Solution Explorer.
Step # 3
Next, you have to make sure that you set up the library you want to use. You can do that by configuring the library in the namespace of the program. In our case, the library we want to use is HtmlAgilityPack.
We’ll also need the .NET Core asynchronous HTTP request libraries.
Edit the Form1.cs namespace so that it looks like this:
using System;
using HtmlAgilityPack;
using System.Net.Http;
using System.Net.Http.Headers;
using System.IO;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
The System library files are included in the namespace by default. This is true for any Windows Form App you design with C#. The additions we made here to the program are the following lines:
using HtmlAgilityPack;
using System.Net.Http;
using System.Net.Http.Headers;
using System.IO;
Step # 4
Once you’ve configured the namespace, it’s time to write the C# HTML parser code.
In the web_scraper namespace, add the following code:
public void parseHtml(string htmlData)
{
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(htmlData);
var table = doc.DocumentNode.Descendants(“tbody”);
var cryptoData = new Dictionary<string, string>();
foreach (var row in table.ToList()[0].ChildNodes)
{
cryptoData.Add(row.ChildNodes[2].InnerText, row.ChildNodes[3].InnerText);
foreach(var column in row.ChildNodes)
{
_ = column.ChildNodes.Count;
}
}
}
There’s a lot to digest here, so let’s walk through the code step by step. If it’s your first time coding with C#, you may find this helpful. Otherwise, you can just skip to the next step.
First, let’s look at the function declaration. The parser we’re building is a void function because it returns no value once the code executes. It only has one string input, which is the htmlData.
public void parseHtml(string htmlData)
In the following line, we’re invoking a function from the HtmlAgilityPack library called HtmlDocument. The new keyword creates a new instance of the HtmlDocument object, which we have titled doc.
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
The doc.LoadHtml uses a built-in method for loading the htmlData to the doc object we created in the previous line.
doc.LoadHtml(htmlData);
Next, we’re creating a variable called table that will store the list of the descendants of the XML nodes in the document. Another built-in method in the HtmlAgilityPack library called DocumentNode tabulates for us.
The string “tbody” is an HTML tag that tells us where the data we wish to scrape begins.
var table = doc.DocumentNode.Descendants(“tbody”);
The cryptoData variable is a dictionary data structure that will take the data.
var cryptoData = new Dictionary<string, string>();
Finally, we are running a nested for-loop in our table, which we first convert to a list using the ToList() method. The loop first iterates over each row in the table list’s child nodes. It populates our dictionary with a key-value pair; in this case, it’s the coin name and the coin price.
The inner loop then iterates over each column in the row and counts the total child nodes in the document.
foreach (var row in table.ToList()[0].ChildNodes)
{
cryptoData.Add(row.ChildNodes[2].InnerText, row.ChildNodes[3].InnerText);
foreach(var column in row.ChildNodes)
{
_ = column.ChildNodes.Count;
}
}
Step # 5
Now that you’ve coded the C# parser, it’s time to add the code for connecting to the URL we want to scrape data from.
The program will use a built-in library method to connect to the URL online and grab the data from there.
Add the following Task code to the web_scraper namespace:
public async Task GetDataFromWebPage()
{
string pageURL = “https://www.coingecko.com/en”;
HttpClient client = new HttpClient();
var response = await client.GetStringAsync(pageURL);
ParseHtml(response);
}
The task above is async, which means it can run in the background before synchronizing with the main program. It waits for a response from the client, and once the page URL has fully loaded, it feeds the response in the ParseHtml() function we coded above.
Finally, the string pageURL below is the website we want to scrape data from. You can add a different webpage to scrape here if you wish, but you must modify the code accordingly.
string pageURL = “https://www.coingecko.com/en”
Step # 6
We’re almost there! The final bit of code left is the WriteToCSV function, saving the web scraping results to a CSV file.
Just add the following code now:
public void WriteToCSV(Dictionary<string, string> cryptoCoinData)
var csvBuilder = new StringBuilder();
foreach (var data in cryptoCoinData)
{
csvBuilder.AppendLine(string.Format(“{0},\”{1}\””, data.Key, data.Value));
}
System.IO.File.WriteAllText(“path”, csvBuilder.ToString());
The csvBuilder is a new instance of the StringBuilder() object where we will copy our data to.
var csvBuilder = new StringBuilder();
Now, we run another for-loop and iterate through each element in our input data. In each iteration, the loop appends the data as a single line in the output .csv file.
foreach (var data in cryptoCoinData)
{
csvBuilder.AppendLine(string.Format(“{0},\”{1}\””, data.Key, data.Value));
}
Finally, where it says “path” in the File.WriteAllText method input, add the directory path where you want to save your file. As an example, your path could look something like this:
“C:\\Users\\Rayobyte\\Desktop\\RayobyteWebScraping.csv”
Step # 7
You’re done! Once you put all the code together, go to Build > Build Solution in Visual Studio to compile your build. Alternatively, you can use the keyboard shortcut Ctrl + Shift + B.
If everything is running smoothly, you should be able to see a blank Windows Form app run. The output file should be saved to the directory you chose as a .csv file.
If you do not see the desired output, try to troubleshoot your code for any bugs. Visual Studio’s built-in debugger is excellent for this task.
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, Playwright-compatible.
What are other uses for C# web scraping?
The sky’s the limit when you use C# to scrape web pages. Wherever there is a web page with inputs and data, chances are you’ll be able to scrape it with a C# web scraper.
To get you inspired, here are some use cases of web scraping. These are all examples of what you can do with a C# web scraper:
E-Commerce
Do you run an E-commerce store and are looking to analyze your competitor’s products and prices? Or are you a shopper wanting to compare prices from different retailers? In both cases, you can use a web scraper to extract product details, prices, reviews, and other data from websites.
Lead generation
Lead generation is the cornerstone of any successful product launch. That said, any successful lead generation campaign requires detailed data about potential customers. Fortunately, web scraping can help with the data collection process that can later be used to generate leads.
Academic research
Are you looking for data for your research project? Or do you just want to do a deep literature search of all the research papers along with author names for a particular topic? Either way, a web scraper can help you speed up your research efforts significantly.
Training of machine learning models
Machine learning, deep learning, and neural networks are all the rage these days. All these AI methods have one thing in common: they require massive amounts of data for model training. When training data is not readily available, a web scraper can help build data sets from online sources.
Real estate
With thousands of property listings and prices to compare, the real estate sector is an excellent example of web scraping. You can use a C# web scraper to extract property listings, prices, and locations from major real estate websites. Not only that, but you can also get the contact details of property agents and owners.
Travel
Have an upcoming trip but don’t know the best hotel prices and ratings? A web scraper can help you out. A C# web scraper can collect hotel ratings, prices, and reviews from travel websites. Similarly, you can also collect data to compare the prices of different airlines and their flight routes.
Most Common Pitfalls of Web Scraping With C#

So far, a C# web scraper seems like a powerful and versatile tool. However, a tool is only as good as the person who uses it. The same is the case with a C# web scraper.
Often, you’ll face some hurdles while web scraping. A lot of these barriers can easily be fixed with some changes in the code. Others, however, are trickier to account for.
Here are some of the common pitfalls you can face while web scraping with C#:
Triggering CAPTCHA
Remember all those times you tried to access a website but were redirected to a CAPTCHA? Perhaps you had to identify a certain kind of object from an image set (e.g., bicycles), or you were asked to enter image text into a text box?
It turns out those weren’t just there to annoy you. As any web scraper can testify, CAPTCHA is a standard security measure to detect bots. Most of the time, anti-bot security measures will trigger a CAPTCHA response from the target web page.
If your web scraper triggers a CAPTCHA response, it’s already too late. CAPTCHA is designed to be unbeatable by bots, so the winning move is not to play at all — that is, not run into CAPTCHA in the first place.
One way to prevent running into CAPTCHA is to use proxies, which we’ll talk about in a moment.
Honeypots
Just like a fly swarms to sweet honey only to get stuck in it, a web scraper can also get stuck in a honeypot. In the context of web scraping, honeypots are links meant to lure and trap web scraping bots.
Honeypots are often web links invisible to humans browsing the website but not to bots in the code. To the unsuspecting bot, the honeypot is still a web link to parse through and scrape. Unfortunately, a bot stuck in a honeypot will alert the webmaster of unscrupulous activity.
Most of the time, honeypots are recognizable by their features. For example, you may see a link with a nofollow tag or a link with the CSS element display: none. Sometimes, the link may also be visible but have the same color as the background page.
The only reliable way to avoid honeypots is to use detection logic. However, this logic can be both difficult and time-consuming to implement for most programmers. For this reason, a pre-built program with anti-honeypot logic is your best bet.
Poor crawling patterns
Too fast, too similar, or too bot-like; these are all examples of poor web crawling patterns. A poorly designed C# web crawler will not account for the differences in how a human browses a web page compared to a machine. As such, bots with poor crawling patterns are likely to be weeded out by vigilant webmasters.
If you’re wondering how to scrape without bans in C#, using smart crawling patterns is often the first step. A C# web crawler that crawls too fast can increase the load on the website significantly. This fast crawling may affect the website as a denial of service (DoS) cyberattack and raise some red flags.
Similarly, bots that follow a similar crawling pattern over and over again will appear too repetitive compared to a human. Humans browse web pages much less repetitively and have actions such as random mouse clicks or page scrolls.
A good workaround to this issue is to use smart crawling patterns and frequencies that more closely mimic a human’s. Again, coding such logic may not be the most straightforward task for most developers to accomplish from scratch.
IP bans and blacklisting
The kryptonite of any web scraper, IP bans are one of the most common pitfalls you’ll face while web scraping. A milder outcome is the still-dreaded blacklist, where the webmaster can only ban your IP from accessing specific content.
Honeypots, CAPTCHA, and poor crawling patterns can all result in IP bans or blacklists. Once your IP gets banned, there is unfortunately not a lot you can do to unban it.
A poorly coded C# web scraper will not account for the pitfalls mentioned above. As such, these bots are bound to be blacklisted sooner or later.
Just like beating CAPTCHA, the winning move against IP bans is not to get banned at all. Fortunately, this is relatively straightforward to accomplish as long as you use proxies.
Data spoofing
If IP bans and blacklists are like death for web scrapers, could there be a fate worse than death? Unfortunately, the answer is yes: it’s called data spoofing.
It’s one thing to be banned from a website entirely and not get the data you want. It’s even worse to scrape data believed to be genuine but which is otherwise fabricated or laced with misinformation.
More tech-savvy web admins know web scrapers and don’t want anyone snooping around to collect their data. That’s why they can set up data spoofing measures to corrupt the data web scrapers collect. This data corruption can lead to significant losses, as it can distort the results of data analysis.
Unfortunately, there’s no sure-fire way to prevent data spoofing without having a valid source to compare your web scraping results to. That said, some currently existing solutions can help safeguard data scrapers against data spoofing.
How to Speed Up Web Scraping With C#

Fortunately, there are workarounds to most of the pitfalls of web scraping with C#. By adopting the best practices of web scraping with C#, you can avoid any hurdles and speed up your web scraping tremendously.
Additionally, there are some other ways to speed up your C# web scraper that depends on how you code the web scraper to begin with. We’ll also discuss these below, along with how you can protect yourself from the previously mentioned pitfalls.
In no particular order, here are some of the best practices to speed up web scraping with C#:
Create a .NET core web application project
We created a web scraper using the Windows Forms App (.NET Framework) project template in our example. As it turns out, this template is not the most optimal one for building a C# web scraper.
You can instead create a better web scraper application by switching to the ASP.NET Core Web App instead. There are some additional libraries in the .NET Core framework, such as the asynchronous HTTP request libraries. These libraries can make it much easier to fetch data from a static, asynchronous website.
Use more efficient data structures
The efficiency of a program can increase or decrease depending on what kind of Abstract Data Type (ADT) you implement in the program. An implementation of an ADT is known as a data structure. The runtime efficiency of data structures and other programs is measured in Big-O notation.
Our example used the pre-existing dictionary data structure in C#. The time complexity of a search operation in a dictionary is O(N), where N is the number of inputs in the program. The time complexity of an add operation is O(1); you can add a new entry to a dictionary in constant time.
An example of a better data structure than a dictionary for data with key-value pairs is a hash table. The hash table ADT provides an average O(1) lookup time both for the search and insert operations, which is better than the O(N) insert time of dictionaries.
On the other hand, you might see a C# web crawler that uses a list data structure to parse through a web page instead:
List<string> webLinks = new List<string>();
In C#, a list data structure has O(N) lookup time compared to a dictionary’s O(1). A C# program that uses a list data structure to store web nodes will perform much slower than one that uses a more efficient data structure. This is especially true for programs with large data inputs.
Use headless web browsers
Rather than run a standard web browser, it is possible to web scrape using a headless web browser instead. Headless web browsers don’t have a UI, nor do they display images. To interact with this headless browser instance, you must use the Command Line Interface (CLI) instead.
The advantage of headless web browsers is that they are much faster than traditional web browsers. This speed is because headless browsers don’t render web pages for users to see, so they save on computing resources. For larger web scraping applications, this can be a huge advantage.
As an example, you can use the PuppeteerSharp or Selenium libraries with the Headless Chrome Browser.
To use PuppeteerSharp, you must first download the library from the NuGet Package Manager inside Visual Studio. Then, you need to include the package in your C# web scraper namespace by adding the following line:
using PuppeteerSharp;
The documentation for PuppeteerSharp is available from the official Google developer website. This documentation includes a tutorial for setting up PuppeteerSharp and standard C# methods so you can browse through it at your own pace.
If you don’t wish to use PuppeteerSharp, you can use the Selenium library instead. You can add Selenium to your project by adding the following lines to your project namespace:
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
Naturally, you’ll also need to download and install Selenium.WebDriver and Selenium.WebDriver.ChromeDriver from the NuGet Package manager. There are different Selenium drivers for other browsers, so you’ll need to download the driver for that instead if you’re using Headless Firefox.
Scrape using proxies
As previously mentioned, some sites have checks and traps in place for detecting bots.
Fortunately, there is a relatively simple workaround to this problem: scrape websites using web proxies.
To use proxies in C#, add the following lines to your namespace:
using System.IO;
using System.Net;
using System.Web;
Then, in the namespace of your program, add the following function:
public static void proxyConnect()
WebProxy proxy = new WebProxy();
proxy.address = “http://IP:Port”;
HTTPWebRequest req = (HTTPWebRequest) WebRequest.Create(“https://rayobyte.com/”);
req.proxy = proxy;
HTTPWebResponse res = req.GetResponse();
string src = new StreamReader(re.GetResponseStream()).ReadToEnd();
}
}
In the line below, you’ll have to add the proxy address and port in place of IP:Port.
proxy.address = “http://IP:Port”;
If you successfully execute the code above, you should be able to make an HTTPWebRequest in C# using the proxy connection of your choice.
Seems complicated? The good news is there is a simpler solution: Use the Proxy Pilot management application. Proxy Pilot proxy management is easy to integrate with your existing C# web scraper; just add a few lines of code to your HTTP requests, and you can connect to proxies effortlessly.
What’s more, Proxy Pilot comes pre-packaged with the following features:
- Retry handling: Handle retry and IP rotation logic automatically without hard-coding it in your C# parser.
- Ban detection: Check for IP bans using advanced methods such as full HTML document parsing, HTTP code, and URL regex.
- Cooldown logic: Manage cooldowns between reusing rotating IP addresses in an undetectable manner.
These features can all safeguard the web scraper against poor crawling patterns, honeypots, and even triggering CAPTCHA. These pitfalls usually are too difficult to avoid for programmers, as the logic is difficult to code from scratch. Fortunately, Proxy Pilot comes pre-packaged with the logic needed to prevent these pitfalls and more.
The Best Proxies to Use for Web Scraping C#

A proxy is a must-have for any C# web scraper worth its salt. However, not all proxies are created equal. Some better prevent pitfalls like honeypots as captchas, others not so much.
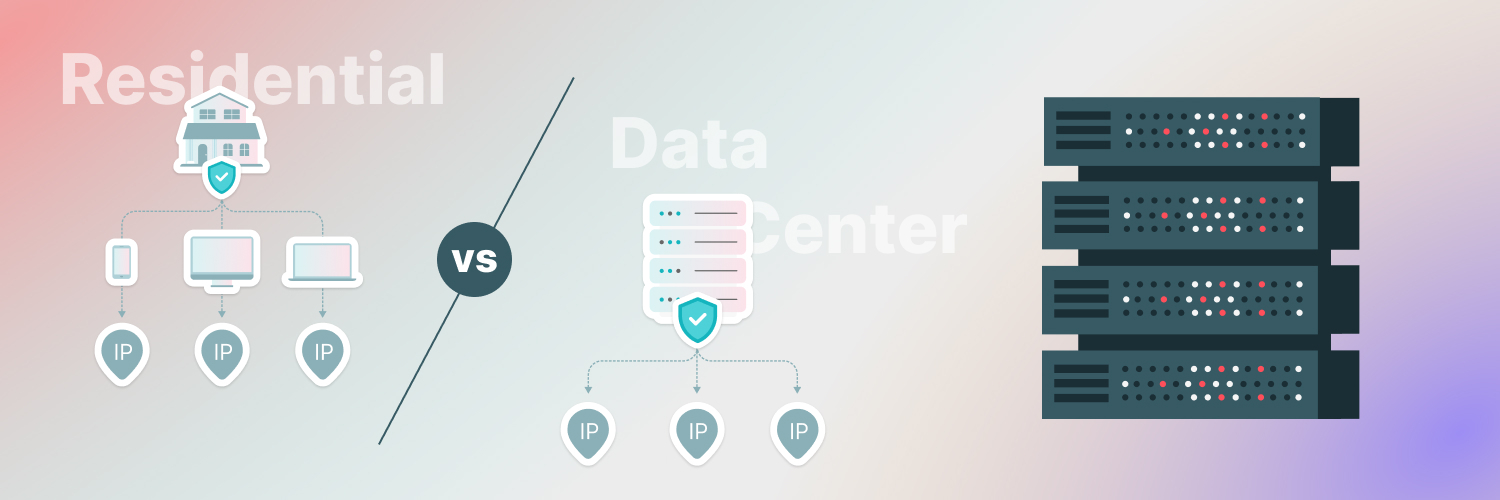
If you use a single proxy for too long, you risk getting an IP ban or blacklist. The solution for how to web scrape without bans in C# ? Use rotating residential proxies. By choosing a specific location to scrape from and constantly changing the IP address, your web scraper can become virtually bulletproof when it comes to IP bans.
Rayobyte rotating residential IPs are your best bet when it comes to rotating proxies. Rather than manually rotating your IP address, you can configure rayobyte rotating residential IPs to swap your IP addresses automatically after a while.
Instead of having to rely on multiple proxy providers to do all the rotation for you, you can use Rayobyte proxies as a one-stop solution for all your proxy needs. This solution makes it much easier to integrate proxies with your web scraper.
The best part? Each purchase of Rayobyte Residential Proxies comes absolutely free with Proxy Pilot!
Not only can Proxy Pilot help you stay safe from web scraping pitfalls, but it also does so independently of any third-party libraries. All the web scraping logic you’ll ever need for your C# web scraper comes built-in with Proxy Pilot.
In other words, Rayobyte proxies are all you need to purchase as a sole solution for your C# web scraper —the rest is completely free!
Conclusion

As the World Wide Web continues to grow, so will web scraping. As such, web scrapers need to improvise and adapt to the best programming languages for web scraping. Although languages like Python are a popular choice for web scraping today, C# is still a powerful and versatile language that may be even better for coding a web scraper.
Still, a simple web scraper is incomplete. Without using rotating IPs, a C# web scraper can fall into the common pitfalls of web scraping. Get Rayobyte residential IPs today and take your web scraping experience to the next level today!
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, Playwright-compatible.
The information contained within this article, including information posted by official staff, guest-submitted material, message board postings, or other third-party material is presented solely for the purposes of education and furtherance of the knowledge of the reader. All trademarks used in this publication are hereby acknowledged as the property of their respective owners.