The Ultimate Guide To C++ Web Scraping
So you’ve been web scraping for a while. You’ve put in the work, and you’re collecting tons of useful data. However, you think you can do even better. How? By making your own customized web scraper that’s built for your purposes.
That’s a great solution. Still, there’s a lot more to creating a web scraper that works than you might think. For example, you need to choose the right language in which to write your scraper before you do anything else.
One such language is C++. This language is one of the fastest and most efficient programming languages in the world. If you understand C++, it’s the perfect tool to make your next web scraper.
Before diving in, you should understand that this is the ultimate guide on how to make a web scraper in C++. You may only need some of the information it contains. Feel free to use the table of contents below to skip to the information that matters to you.

Why Write a C++ Web Scraping Program?

If you’re considering writing your own web scraping program, you’ll need to choose your programming language wisely. So, why choose C++? Simple: if you know how to code, you probably understand C++. The C family of programming languages is the most common in the world by far. C, C++, and C# hold three of the top five positions in terms of popularity globally. Here’s what you need to know about programming a scraper in C++.
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, Playwright-compatible.

What is C++?
C++ is a general-purpose programming language that’s intended to handle a wide variety of use cases that’s been around since 1979. According to Bjarne Stroustrup, the creator of C++, it was designed to focus on system programming, but it’s improved significantly since it was first released.
Today, it supports object-oriented features and memory manipulation alongside its original features. Essentially, C++ is a relatively flexible language that wasn’t initially built for web use but can easily support practices like web scraping.
Other benefits of C++ include:
- Commonly used: C++ is one of the five most frequently used languages in the programming world. The C family of languages makes up more than a quarter of all programming in the world. Hundreds of thousands of programmers are already familiar with it.
- Huge libraries: Since C++ has been around for decades, there are thousands of libraries you can use in combination with it. There are both free-to-use and paid libraries, so there’s a solution for every budget.
- Lots of support: C++ is actively supported, standardized, and maintained by the International Organization for Standardization. It’s considered so important to the coding world that it’s updated every three years with new standard libraries and features.
Of course, while C++ is popular, it’s not the only language available. Many people choose to use other languages for web scraping. Here’s what you need to know about alternatives like Python and Java and how they stack up against C++.
C++ vs. Python
Python benefits:
- User-friendly
- Open-source
- Easy to learn
- Extensive library support
- Dynamically-typed
Python drawbacks:
- No built-in memory safety features
- Slower than C++
C++ benefits:
- Very fast
- Easy installation
- Built-in Type memory safety tool
- Extensive library support
C++ drawbacks:
- Expensive
- Resource-intensive
- Complicated to learn and write
- Statically-typed
Python is a simple language that’s often used to write quick web scraping programs. It’s known for being fast and flexible, and it’s designed to work well online. Plus, Python is relatively easy to learn since it was created to be parsed by humans. It’s also open-source, so it’s free to use.
However, Python isn’t the best choice for large datasets. It doesn’t have memory safety features, so too much data unexpectedly can cause problems. Furthermore, Python programs can get long specifically because the actual commands are so simple.
Verdict: If you understand C++ or you need to collect large amounts of information, C++ is the way to go. On the other hand, if you’re trying to choose a language to learn, it will be easier to pick up Python for your first programs.
C++ vs. Java
C++ benefits:
- Supports header files
- Very fast
- Significant library support
- Shorter to write
C++ drawbacks:
- Platform dependent
- Resource-intensive
- Harder to learn
Java benefits:
- Platform independent
- User friendly
- Built for online applications
- Built-in thread support
Java drawbacks:
- Gets very long, takes time to write
- Slower than C++
- Doesn’t support header files
Java is known as a platform-independent programming language. It doesn’t require a separate compiler to run like C++. It’s also one of the main languages used for web application development. It’s quite fast, too, though not quite as fast as C++.
On the other hand, Java isn’t the most accessible program to learn. It’s simpler than C++, but it’s not as easy to understand as Python. Furthermore, Java programs get very long, very quickly. Finally, it’s not open-source, so it’s an investment, just like C++.
Verdict: If you already know and work with Java, then you may be better off writing a Java web scraper. However, if you have the resources and experience, C++ is a better solution.
How to Scrape Data from a Website with C++

Before you can write a scraper, you need to understand how the scraping process actually works. It’s one thing to understand it well enough to use someone else’s scraper, and it’s another altogether to write your own.
Understand how C++ HTML parsers work
All web crawlers look for information on web pages by reading the site’s HTML. Most sites have well-structured HTML that can be read as a “tree” with a good parser. A C++ HTML parser examines the code that makes up a site and looks for specific “elements” and “tags” that you’ve told it to find.
Once it finds that data, the web scraper should collect the information you want and print it out into the file you’ve chosen. Think of it like a squirrel running around a tree and pulling off acorns.
If you want your scraper to collect valuable information, you need to do your homework.
Determine the data you want to scrape
First, make sure you know what information you actually want. Do you want links? Dates? Prices and product names? Phone numbers? All of these can be collected with a good scraper, but you need to have a specific goal before you go any further.
Next, you need to do a little investigation on your own. Web scrapers are incredibly literal. You need to know exactly how information is stored on a web page if you want the scraper to find it.
Arm your web scraping tool with information
Go to the site you’re going to scrape and spend some time studying the code. Figure out how the site programmer structured the page and where the information is held. If you can identify patterns, you can use them in your scraper’s programming to grab the data you want.
You can also look at the structure of the site overall. If you want to collect information from multiple pages of the same site, it’s valuable to understand how the links and URLs are structured. For example, some sites use sequential digits to differentiate pages, while others have unique URLs on every page. This information will come in handy later, so figure it out now.
Once you’re done with your research, you can actually start writing your C++ web scraper.
The Benefits of Visual Studio Web Scraping

When it comes to writing in C++, it’s a good idea to use a solid IDE for your coding environment. IDEs help you manage a variety of challenges. They’re designed as multi-purpose software that help you consolidate a lot of different tasks all in one place. In general, they let programmers access tools and features in the same program where they’re writing their code, streamlining the writing process.
A good IDE will have features like:
- Automated code testing and compiling
- Library storage for each program you write
- Debugging features to spot errors before running the code
- A Graphical User Interface (GUI) that displays code features in different colors to help you keep track of what you’re writing
Altogether, these features make it much easier to write code that works the first time. However, not every IDE works for every language.
If you’re writing a C++ program, Virtual Studio is one of the best IDEs available. It’s specifically built to handle the C family of languages. Visual Studio Projects, for example, has all of the above features along with extra benefits like:
- Change tracking to easily undo changes that broke the program
- IntelliSense suggestions and syntax checks to help you improve your code while you’re writing
- Collaboration features to let multiple people work on the same project and fine-tune it
Basically, if you’re trying to build a great C++ web scraper, Visual Studio is the fastest and most efficient way to go about it.
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, Playwright-compatible.
How to Make a C++ Web Crawler

While C++ is definitely older than some other web scraper languages, that’s actually a benefit for many programmers. Its age and ubiquity mean that there are many more resources available for people working with it. If you’re familiar with C++, you’ll be able to follow along with this C++ web scraping tutorial and write a scraper that fits your requirements.
1. Choose your coding environment
The first step of any coding project is installing a language compiler on your computer. A compiler is a program that converts C++ to computer code. Without one, computers can’t translate human-written code into instructions they can actually follow.
You’ll also need a coding environment. This is the place where you actually type the code. A coding environment can be nothing more than a text file, but many people prefer to work in Integrated Development Environments (IDEs). These are programs that make coding easier by pointing out errors in the code and helping you format it correctly.
Visual Studio, as mentioned above, is a coding environment plus a compiler, and it’s the best option for most people writing in C++. In the rest of this tutorial, it’s assumed that you’re creating a website scraper in Visual Studio.
2. Install some fundamental tools
Your IDE is just one of the tools that you’ll need to make a good web scraper. If you don’t want to make everything from scratch, you should use a few other libraries and programs to make your life easier. This tutorial will assume that you’re also using the following tools.
vcpkg
Before you download any libraries or tools, you’ll need a way to actually manage them. That’s what vcpkg does. It’s a C/C++ package manager that’s designed to help you acquire and manage libraries. Without it, you can’t actually implement new libraries in C++. You can add vcpkg to your program with the following:
git clone https://github.com/Microsoft/vcpkg
.\vcpkg\bootstrap-vcpkg.bat
cpr
The cpr library is a C and C++ library to support HTTP requests. It acts as a wrapper around libcurl, which is a crucial library for any C-based programs that involve internet data transfers. Many programmers prefer to use cpr alongside libcurl because libcurl C++ is known for being extremely dense. By acting as a wrapper, the cpr library makes it easier to use libcurl without being an expert in C++.
To use cpr, you’ll need to install it with vcpkg with the following command:
.\vcpkg\vcpkg install cpr
The cpr install is always kept up-to-date by the Microsoft team and community, so you’ll never need to worry about out-of-date ports.
gumbo
Last but not least, gumbo is an HTML parser that will be fundamental to your scraper. It’s a lightweight parser that doesn’t require any external dependencies. A good HTML parser helps your program understand the different elements of HTML, which will let your C++ web scraper read and collect the data you want. Install gumbo with the following line:
.\vcpkg\vcpkg install gumbo
Once these tools are installed, you can add the next line to make sure they’re appropriately integrated:
.\vcpkg\vcpkg integrate install
You’ll also use a few libraries that come standard with C++: fstream and iostream. To make all of your libraries and parsers work, write:
#include “gumbo.h”
#include “cpr/cpr.h”
#include <iostream>
#include <fstream>
This tells the program that it will specifically be using those libraries.
3. Target a webpage
Now it’s time to get into the meat of your program. First, you need to designate that the HTML will be a string. To do that, use “std::string” to set the name. For example:
std::string webpage_html()
Next, we’re going to tell cpr what to do to create that string:
cpr::Response r = cpr::Get(crp::Url{https://www.songfacts.com/songs/queen});
return r.text;
This does three things. First, it grabs the HTML from the SongFacts page “Queen.” Second, it sets that HTML as the response object “r” so you can refer to it later. Finally, it sets the text of “r” (“r.text”) as the string to be returned by “webpage_html” listed above.
4. Read the HTML data
The next step is to actually examine the HTML and pull out the information you care about. The text parser gumbo is going to help you out.
First, we need to set a main function for the program. All the work prior to this is essentially just gathering information. The main function lets the program know that things are about to start happening. To start:
int main()
Next, we can start transforming the string.
std::string read_html = webpage_html();
GumboOutput* cooked_gumbo = gumbo_parse(read_html.c_str());
This tells gumbo to convert the HTML we’ve collected into an HTML tree. Next, we want to tell it what to do with that tree:
find_song_titles(cooked_gumbo->root);
gumbo_destroy_output(&kGumboDefaultOptions, cooked_gumbo);
This names the function of the search “find_song_titles” and helps you program save memory once the search is done.
5. Extract information
It’s finally time to tell gumbo what to do with all that information. Now we’re going to get into some loops that will collect the data we care about. We’re going to use a convenient loop found on StackOverflow, which is an excellent reference for any questions you have about C++.
void find_song_title(GumboNode* node)
if (node->v.element.tag == GUMBO_TAG_A &&
(href = gumbo_get_attribute(&node->v.element.attributes, “href”))
QString strTitle;
GumboNode* title_text = static_cast<GumboNode>*)(node->v.element.children.data[0]);
if (title_text->type == GUMBO_NODE_TEXT)
strTitle = title_text->v.text.text;
}
return;
This loop identifies all “a href” elements on the page, then extracts the data from within the links.
We’ll also need a few other loop elements:
if (node->type != GUMBO_NODE_ELEMENT)
return;
This tells the loop to ignore anything that isn’t a gumbo node element.
6. Collect the data in a file
We’re almost to the end. The last step you need to complete is actually saving all of your information to a file that you can use to study it. For simplicity’s sake, we’ll export it to a .txt file.
To do this, we’ll back up to the beginning of the document and open a .txt file.
std::ofstream writeTxt (“output.txt”);
Next, we’ll write the content of the file in the “find_song_titles” function. Under the “if (node->v.element.tag == GUMBO_TAG_A), we’ll add another if loop.
Std:: string title = href->value;
if (title.rfind(“/facts/queen) == 0)
writeTxt << title << “\n”;
else
writeTxt << “\n”;
The complete program
You’re done! C++ has some complex elements, but it’s a powerful and fast tool for writing web scrapers. When you understand how your web scrapers work, you can use C++ to print out the information you’ve collected all in one place.
Don’t be afraid to play around with the structure of your scraper, either. It’s easy to adjust the program to collect other kinds of information, send information to a CSV file, and scrape multiple pages. The foundation you’ve built can be used to do whatever you need it to do. Here’s what the program looks like all in one place:
git clone https://github.com/Microsoft/vcpkg
.\vcpkg\bootstrap-vcpkg.bat
.\vcpkg\vcpkg install cpr
.\vcpkg\vcpkg install gumbo
.\vcpkg\vcpkg integrate install
#include “gumbo.h”
#include “cpr/cpr.h”
#include <iostream>
#include <fstream>
std::ofstream writeTxt (“output.txt”);
cpr::Response r = cpr::Get(cpr::Url{https://www.songfacts.com/songs/queen});
return r.text;
int main()
std::string read_html = webpage_html();
GumboOutput* cooked_gumbo = gumbo_parse(read_html.c_str());
find_song_titles(cooked_gumbo->root);
gumbo_destroy_output(&kGumboDefaultOptions, cooked_gumbo);
void find_song_title(GumboNode* node)
if (node->v.element.tag == GUMBO_TAG_A &&
(href = gumbo_get_attribute(&node->v.element.attributes, “href”))
QString strTitle;
GumboNode* title_text = static_cast<GumboNode>*)(node->v.element.children.data[0]);
if (title_text->type == GUMBO_NODE_TEXT)
strTitle = title_text->v.text.text;
Std:: string title = href->value;
if (title.rfind(“/facts/queen) == 0)
writeTxt << title << “\n”;
else
writeTxt << “\n”;
return;
if (node->type != GUMBO_NODE_ELEMENT)
return;
Ways to Use a C++ Web Scraper

Once you’ve written your C++ web crawler, it’s only natural that you want to use it as soon as possible. While you probably already use web scrapers for data collection, there’s so much more you can do with them.
A great way for businesses to use C++ web scrapers is to collect reviews about their competitors’ products. These scrapes target information like product names, descriptions, and customer feedback from online retail sites. With this information, businesses can analyze what people like and dislike about the competition and potentially improve their own products to become more competitive.
Web scraping isn’t restricted to the business world, either. Anyone with access to C++ can use it to collect data about things like concert tickets or game consoles. For example, if you’re trying to purchase an Xbox, you could scrape retail and auction sites to find the sellers who are offering the best deal and have the consoles in stock.
Other ways you can use web scraping include:
- Social media: Many social media sites are goldmines of information about everything from customer sentiment to concert dates. You can scrape social media to collect vast amounts of information about what people think about your brand and how often people are talking about you.
- Pricing: Companies need to offer competitive pricing to make sales. You can scrape competitors’ sites to discover what they charge for different products and even identify common deals that you should consider.
- Travel: Whether you’re traveling for business or pleasure, it’s important to get a good deal. You can scrape travel and hotel sites to find the dates and times that will make your next trip more cost-effective.
- Research and statistics: Not every web scrape needs to be directly related to money. The web is a great place to collect information about what people think and how they act. Web scraping can collect the information you need for your next research project.
C++ Web Scraping Best Practices

The tools you’ve just learned are just the beginning when it comes to C++ web scraping. There are plenty of best practices and tactics you can use that will refine your program even further. These tips and tricks will help you upgrade your entry-level C++ web scraper into a top-tier data collection solution.
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, Playwright-compatible.
Check multiple pages at a time
In the time it takes to write a functional web scraper, you could visit a single page and copy and paste the information you want. It’s much more efficient to use your scraper to examine multiple URLs in a single session.
For loops are your friends here. With a simple for loop and array of URLs, you can easily scrape as many pages as you want.
in urls[3] = “url1”, “url2”, “url3”];
for(int i = 0; i < 3, i++) {
std::site_url << urls[i] << “\n”;
You can place the object “site_url” in the place of the URL in the code above. Then add the rest of the code just after the main function above, and you’ll cycle through all the URLs you’ve listed above during your program.
Implement monitor loops
A great way to use a web crawler is to collect data that’s only available occasionally. Many sites will only display information once or at certain times of day. If you want to make sure you’re on top of updates, you can set your web crawler to check up on sites with a monitoring loop.
A monitoring loop is just that: it’s a loop that rechecks the designated URLs at specified times. It performs a new scrape at regular intervals, giving you the chance to look for updates and changes.
The easiest way to set up a monitoring process in a C++ web scraper is with the “sleep_for” and “sleep_until” functions. You can easily add these to your program with the code below directly under the main function:
#include chrono
#include thread
using namespace std::this_session;
using namespace std::chrono;
sleep_for(minutes(10));
This code will cause your program to sleep for ten minutes before it runs again. You can also replace “sleep_for(minutes(10))” with “sleep_until(systemclock::now() + minutes(10))” to specify how long the program should sleep. Customize the amount of time you want the program to rest by adjusting the minutes to seconds, nanoseconds, hours, or days, and change the integer to whatever you want.
Use proxies
You should always use proxies when you’re putting together a web scraper. Many sites watch for web crawlers and have security measures intended to block them. One of the most common ways web scrapers are identified is based on the IP address of the program. If your scraper sends too many requests in a short period from the same IP address, you could get banned and ruin your results.
Conveniently, cpr has a specific toolset for adding proxies to your program:
cpr::Session session
session.SetProxies({{“http”, “put.proxy.site.here”},
{“https”, “put.proxy.site.here”}})
Session.SetUrl(“http://put.goal.url.here”);
cpr::Response r = session.Get();
std::cout << r.curl << std::endl;
Session.SetUrl(“https://put.goal.url.here”);
cpr::Response r = session.Get();
std::cout << r.curl << std::endl;
This bit of code lets you connect different proxies from your HTTP and HTTPS requests across a session. You can also use the Proxy Pilot proxy management application. This program is easy to add to any C++ program, and it will neatly manage your proxies for you without needing to handle them personally.
Mimic human scraping patterns
You can also make your C++ web scraping less noticeable by making sure you follow human scraping patterns. Without any external help, the cpr library can be too accurate and quick. It can give away that your program isn’t a natural person by visiting too many sites and spending precisely the same amount of time on each one.
That’s an obvious sign that the visit is from a bot and not a person. The easiest way to add a little bit of space between your searches is by combining the “sleep_for” and “srand” commands. At the end of your program, add “sleep_for” and designate a random time with the srand function, and the program will always wait an arbitrary number of seconds before going to the next page. This makes it less evident that a bot is visiting and helps protect your proxies from getting blocked.
The 8 Most Common Complications with C++ Web Scraping

The last but most crucial element of writing a web scraper is watching out for bugs. The internet is a complicated place, and even the best programmers need to refine their bots over time. As you use your new scraping program, you’ll inevitably run into problems.
However, most of these can be addressed with minor changes to your web scraper. Here’s how to fix and avoid the eight most common problems that C++ web scrapers run into.
- CAPTCHA walls: If your program is frequently running into page timeouts, it may be getting stuck on CAPTCHAs that it can’t solve. Check for CAPTCHAs by visiting sites personally or running your scraping program within a headed browser. The best solution to avoiding CAPTCHAs is implementing rotating residential proxies.
- Logins and authentication: Many sites force visitors to log in before they can access the content. Without the proper authentication, the bot will get an error and never reach the page. To log in with your scraper, use browser-based developr tools to figure out what the site wants from the header. You can then use the cpr HTML request to add the right information.
- Asynchronous loading: One of the most significant issues interrupting web scrapers is asynchronous loading. It’s responsible for many scrapes that only collect a fraction of the information you anticipated. Replace your cpr library with a browser instance like WebBrowser to force the page to load the JavaScript appropriately.
- iframe tags: Like asynchronous loading, iframe tags display content that isn’t actually found in the site’s HTML. The easiest way to scrape iframe tags is to collect the src attribute within the tag. Gather all the src URLS you want to scrape, then run a second scrape that targets those specific pages.
- Redirects: Many pages online will redirect you to another page. If your bot is getting lots of 3XX errors, it’s probably running into redirects. You can navigate around redirects by capturing the new URL system. Follow the redirects manually and find the latest pattern so you can update your URL arrays.
- Strict header requirements: Some sites perform header inspections to filter out suspicious visitors. These sites check the header and the user-agent field to see if it’s likely that the user-agent is a bot. You can avoid this by designating your user-agent field to rotate in in synch with your proxies.
- Honeypot traps: Sites that are especially wary about bots may add honeypot traps to their code behind invisible CSS elements. If your bot is getting blocked even with proxies and rotating user-agents, it may be triggering honeypots. You can neatly avoid these traps by instructing the program to ignore non-visible CSS elements.
- Messy HTML: The biggest challenge to any scraper is a site with bad HTML. If there’s no pattern to follow, your bot won’t be able to pull data. Unfortunately, messy HTML is hard to fix. Look into adding regular expressions to your bot to start cutting through the mess.
The Best C++ Web Proxy for Web Scraping

Proxies are an essential part of any large web scraping project. They’re vital for protecting your personal or business IP address and preventing your scrape from being detected. However, not all proxies are created equal. There are strong, safe proxies, but there are also insecure ones that put your system at risk. So how do you choose?
Here are some things to consider when choosing your proxy.
Keep your scraping ethical
First, you should use proxies from a trusted provider like Rayobyte. By going through a secure provider, you can trust that the proxies you’re using are safe and reliable.
Rotate proxies to avoid site bans
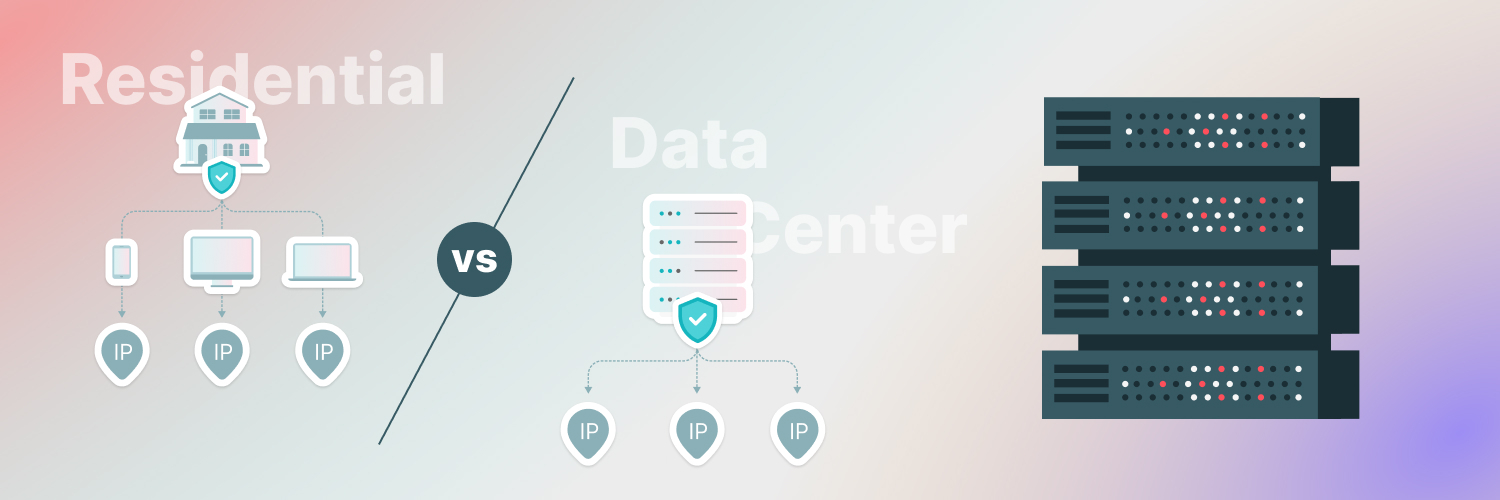
The absolute best solution is to use Rayobyte’s rotating residential proxies. These proxies route your traffic through IP addresses connected to someone’s personal residence. They also rotate, or swap new proxies in for the old ones on a set schedule.
Why is this so useful? For two reasons. Since the proxies automatically and regularly change, a single IP address rarely pings the same site for long enough to be noticed and banned. As a result, your proxies are more reliable over longer searches. Furthermore, since the proxies look like a residential IP, many sites will hesitate to ban them even if they are detected. The two-fold protection means that rotating residential proxies are some of the most reliable and hands-off proxy solutions available.
Use a proxy management system
Rayobyte’s proxies offer other benefits, too. The Proxy Pilot program uses Rayobyte proxies and manages a broad range of management tasks for you. For example, this free solution can automatically manage the logic behind rotating the proxies and letting them “cool down” between uses. It also helps with proxy retries, so you never have to worry about a proxy ban ruining your entire scrape.
If you’re working with Rayobyte residential proxies, you don’t need to do anything to use Proxy Pilot. It’s built into the proxies from the beginning. That means that Rayobyte proxies are well-suited to use in web scrapers. Furthermore, Proxy Pilot is easy to integrate into any C++ program, so you have one less thing to worry about when programming.
Moving Forward with C++ Web Scrapers

You’ve reached the end! If you’ve read the whole guide, you now understand why people use C++ to write web scrapers, how web crawlers work, and how to write a solid C++ web crawler. You’ve also learned some best practices for improving a basic scraping program and how to address some common web scraping problems. You’re prepared to dive into the world of custom web scraping with C++.
If you’re ready to get started, take the first step to make your C++ web scraper even better by supporting it with the best proxies on the market. You’ll protect your IP address and keep your scrapes from getting interrupted at the same time. Get started today by learning more about Rayobyte’s residential proxies and discovering everything a good proxy can do for you.
Scrape at Scale With Chromium Stealth Browser
Self-hosted, Linux-first, Playwright-compatible.
The information contained within this article, including information posted by official staff, guest-submitted material, message board postings, or other third-party material is presented solely for the purposes of education and furtherance of the knowledge of the reader. All trademarks used in this publication are hereby acknowledged as the property of their respective owners.