




















Overcoming TLS Fingerprinting in Web Scraping
Today’s web security is much more than working with a server’s public encryption key. There are many more advanced elements revolving around networks, operating systems and supported cipher suites.
TLS fingerprints consider lots of such elements and, if you want to evade detection whilst ethically scraping, an understanding of this process is becoming increasingly more essential.
So, if you made it this far, you’re obviously interested in learning more about TLS fingerprinting. Maybe you’re just curious, or maybe it’s something that’s giving you some trouble. We’re not judging – we’re just happy you’re here 😉
Read on to learn:
- What is TLS Fingerprinting?
- How does the TLS protocol actually work?
- What details are given in a TLS handshake?
- What is JA3 Fingerprinting?
- What is the impact of TLS fingerprinting for web scrapers?
- What can you do to work with or bypass TLS fingerprinting?
- What else do you need to consider?
100% Raw Data, Zero Hassle
Try our web scraper API and let us do the hard work for you!

What is TLS Fingerprinting?
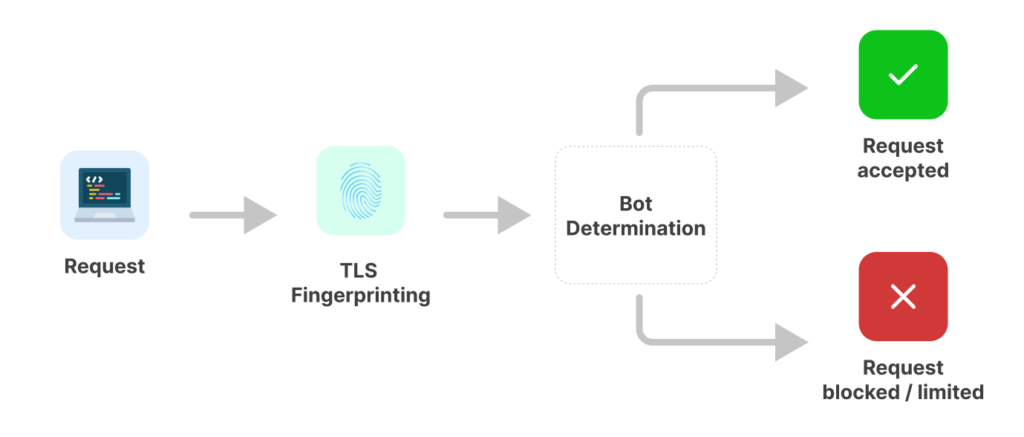
TLS fingerprinting is the process of identifying a device or applicated based on the unique characteristics of its TLS handshake. It is used by website servers and even Web Application Firewalls (WAF) to support security, identifying clients before potentially blocking or allowing their data requests.
TLS, by the way, stands for Transport Layer Security. It’s the cryptographic algorithms used to secure communication over networks. These protocols are fairly common and used in many areas but, for the purposes of web scraping, we’re focusing on their use between web browsers and servers.
In other words, it looks at key signature details of your TLS fingerprint – such as the ciphers, extensions and web browsers used – to determine if you are a valid client. They are used by website servers and even Web Application Firewalls (WAF) to support security, identifying clients before
How Does TLS Fingerprinting Work?
In short, TLS fingerprinting works by analyzing a clients signature details through the exchanges made at the start of a session. It then uses what it learns against known information to deter bots or other unwanted clients from the website.
We can grossly simplify this in three steps:
- A server-side system generates and logs a hash based on information given during the TLS handshake
- It looks up the hash or “fingerprint” in one or more databases of previously known fingerprints. This includes TLS libraries that catalogue the known profiles of various web browser versions.
- Based on what it finds, it takes action. This can range from allowing requests or blocking the connection, but also challenging the connection or assigning the TLS fingerprint a ‘bot likelihood’ score. In any case, the fingerprint is logged for future analysis.

Or if you really want the long version… we’ll use the most common method, JA3 fingerprinting.
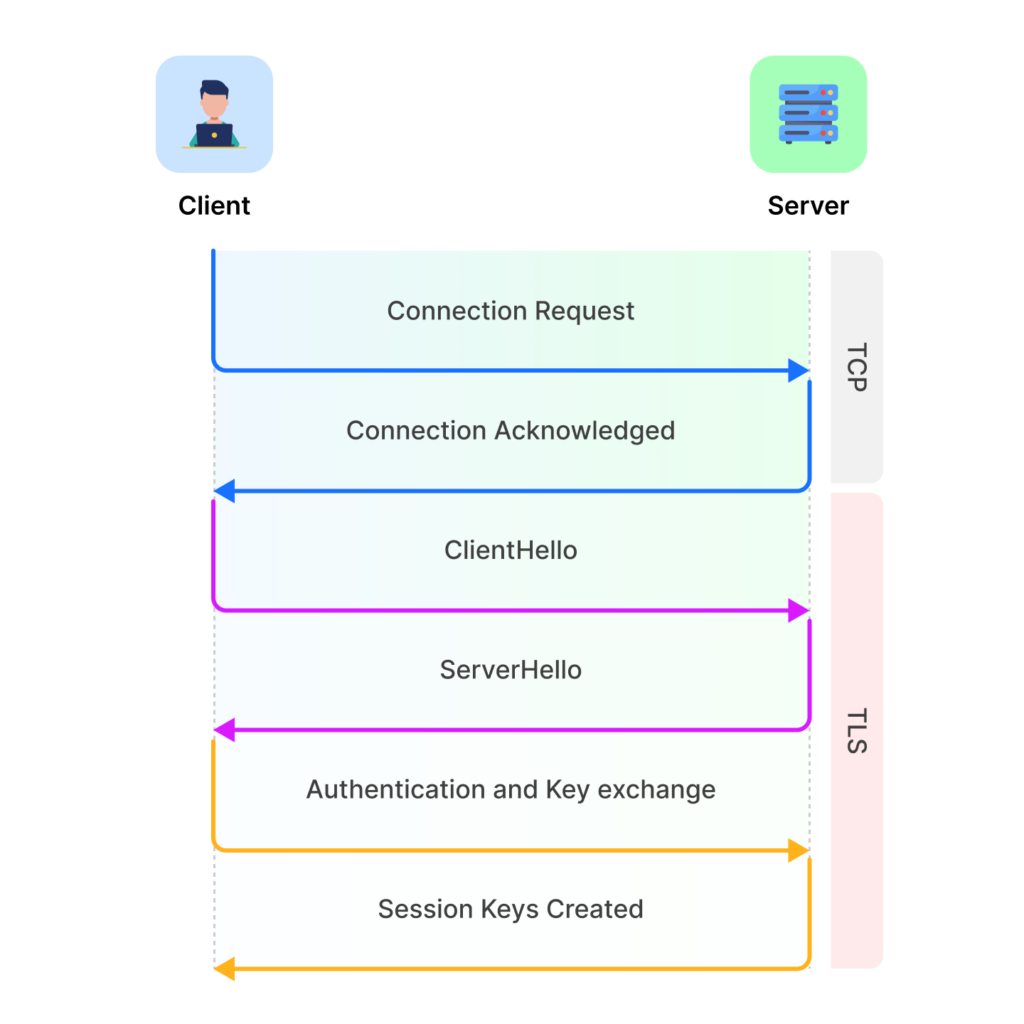
At the start of any session with a website, there is a TLS handshake. Your client, for example, a web browser, app or even a bot, sends a ClientHello message to the respective website’s server. This message lets the server know by what means the client wishes to communicate, including cipher suites, extensions and other TLS specifics.
As part of this TLS protocol, the server learns a lot about you. It can learn the software stack used, including not only the type of browser but also additional language libraries and frameworks, alongside your operating system or device. And it can use many of these things to interpret a valid TLS client from a bot or automated process.
What Does a TLS Fingerprint Consist Of?
So, now we’ve discussed that the TLS protocol uncovers a lot of information, let’s take a deeper look at what’s included in a client hello packet:
- TLS version. This tells the server which specific protocols the client is using.
- Cipher suites. These are the encryption algorithms the client supports, listed in order of preference. This ensures the client and server can establish a secure connection through the most appropriate and agreeable means.
- Supported extensions. This includes a range of optional features that the client may want to use, such as:
- Server Name Indication (SNI) – as it implies, this tells the server the hostname the client is specifically requesting.
- TLS libraries: Each client uses a different range of TLS libraries and cipher suites.
- Application-Layer Protocol Negotiation (ALPN) protocols – this is an extension that allows for additional communication independent from application-layer protocols. For web servers, such TLS extensions are typically HTTP/1.1 or HTTP/2.
- Signature algorithms – these algorithms help the client verify the server’s identity through use on the public key.
- Elliptic curve formats. Elliptic curves are a common approach for encrypted communication, using curved equations across finite fields. In this case, the client hello packet is indicating which curve to use and how the points are encoded.
- Session ID: This is often used for resumed sessions.
Please note that the above is far from complete, but the exact details and nuances of how client hello packets relate to TLS fingerprinting is an in-depth conversation in and of itself.
But what you may have noticed is that none of the above specifically relates to your browser or other direct activity. This is because TLS fingerprinting generally compares these against the variances of known browsers and other aspects of genuine human user activity.
For example:
- An SNI is expected in most requests, so its absence could be a significant red flag for any anti-bot measures.
- Most modern browsers support HTTP/2, so an outdated ALPN request could, again, indicate suspicious activity.
- The supported elliptic curves vary differently between browsers like Chrome and Firefox, and even compared to Python and other programming scripts. This is a big clue regarding what exact application is being used.
There is enough knowledge out there that TLS libraries can make highly educated guesses about who you are – whether you’re a genuine browser or an automated script.
TLS Fingerprinting for Bot Detection
For website owners, detecting bot traffic is one of the biggest benefits of TLS fingerprinting. Because known browsers have their own unique fingerprints – often in the form of supported cipher suites and other extensions – servers can detect the most automated processes, such as purely headless browsers or custom scripts.
Of course, that does lead to a game of cat and mouse. If systems improve their bot detection methods, bots start to implement for human-like features. Like any area of cybersecurity, it is constantly being updated and expanded.
What is The JA3 Fingerprint Method?
While there are numerous different forms of TLS fingerprinting, it’s worth focusing on the most commonly encountered when it comes to secure connections between web browsers and servers. Designed in 2017 by John Althouse, Jeff Atkinson, and Josh Atkins (hence the name), the JA3 fingerprint solution has been open sourced and managed by Salesforce.
Unlike previous TLS fingerprinting methods, JA3 focuses specifically on the client hello packet delivered during the TLS handshake. It then creates a JA3 fingerprint in the form of 32 characters – in the MD5 hash, if you’re interested 😉. Fields are separated by commas and hyphens separate each value of a given field.
Those fields* are, in order: TLSVersion,Ciphers,Extensions,EllipticCurves,EllipticCurvePointFormats
As an example, let’s imagine that a client sends the following information as part of its TLS Client Hello:
- TLS Version: 771 (this corresponds to TLS 1.2)
- Cipher Suites: 4865, 4866, and 4867
- Extensions: 0, 11, 10, 35, 16, 5, 13
- Elliptic Curves (Supported Groups): 29, 23, 24
- Elliptic Curve Point Formats: 0
JA3 would then take these values for TLS fingerprinting, formatting them like this:
771,4865-4866-4867,0-11-10-35-16-5-13,29-23-24,0
And then running this string through an MD5 hash, resulting in:
e7d705a3286e19ea42f587b344ee6865
Then, like any form of TLS fingerprinting, this is compared against one or more databases. This is often an internal database, representing all previous fingerprints generated from client requests. However, it could also use one or more public databases as well. This is common in the cybersecurity field, with popular examples including VirusTotal and Abuse.ch.

You might also see mentions to JA3S – this is the server-side version of JA3, looking at the Server Hello message and generating fingerprints from those particular fields. However, since we’re web scrapers, we’re not questioning the server 😉 But we thought you should know that, together, these processes can help reduce false positives and make the fingerprinting process more accurate.
*You may sometimes see TLS Version as SSL version, as SSL was the precursor to the modern TLS protocol.
What About JA4?
JA4 – a successor to JA3 – is also available, designed to improve accuracy, especially in regards to more modern TLS 1.3 and QUIC/HTTP/3 traffic. While not open-standardized yet, it’s worth being aware of.
Alongside looking outside the scope of the client hello package, JA4 aims to generate shorter fingerprints. Using the same example as above, instead of an MD5 hash, the JA4 fingerprint would look like this:
c12eES
JA4 fingerprints also look at information from TCP-level metadata, including window size, packet size, timestamps and more. Like JA3 and JA3S, JA4 is part of a wider system including JA4S (for Server Hello messages) and JA4X (for QUIC/HTTP3).
The Main Impact for Data Scrapers
The biggest impact of TLS fingerprinting is that it is getting much better at detecting automated solutions.
Unlike older detection methods that relied heavily on IP reputation or header analysis, TLS fingerprinting can spot a mismatch between what your scraper says it is and how it actually behaves at the connection level. That means even if you’re rotating user agents or using residential IPs, your traffic may still be flagged if your TLS handshake doesn’t match that of a legitimate browser.
In some cases, websites use JA3 or JA4 hashes to quickly identify and block traffic coming from popular scraping tools — especially those using default TLS configurations like Python’s requests or httpx. These tools often produce predictable fingerprints that are easy to spot and block.
In other cases, you must also consider the server or proxies you are using. If a website has encountered these proxies before and flagged them as potential bots, or if they’re using a larger, publicly available database, then ‘known’ proxies carry a stronger risk of getting blocked.
This is especially true when proxy traffic is paired with a generic or mismatched TLS fingerprint — it reinforces the impression that your request is coming from a botnet or automation tool.
Awesome, Ethical Proxies Are Just a Few Clicks Away!

Ultimately, for data scrapers, the rise of TLS fingerprinting means you need a more holistic approach: matching browser-level behavior across all layers, rotating TLS fingerprints when possible, and working with high-quality proxies that haven’t been burned. It’s no longer just about what you send — it’s about how you send it.
How Can You Bypass TLS Fingerprinting?
When we talk about bypassing TLS fingerprinting, we’re not actually bypassing it. We’re referring to what we can do to better fit into acceptable TLS parameters and make our resultant fingerprint much more agreeable for the server.
Use a Real Browser
You want to scrape data en masse, we get it. You can still use headless browsers, but you need to choose a high quality one. Puppeteer, Playwright and Selenium all launch actual browsers as part of their processes. Their TLS fingerprints look more like Chrome or Firefox than a custom Python script.
However, we wouldn’t recommend using such browsers straight out of the box. If you’re having trouble with TLS fingerprinting, than a few extra tweaks can help amend those subtle values that might still be causing problems. Speaking of which…
Use Browser-Driven Scraping Libraries
You can support your chosen browser with additional libraries designed to further mimic the TLS fingerprints of real browsers.
Consider using the likes of Puppeteer Stealth, Playwright Stealth and Selenium Stealth for… Puppeteer, Playwright and Selenium, respectively.
TLS Fingerprint Spoofing
We should start by saying it’s not possible to fully, 100% spoof a fingerprint browser, but there are a few things you can do for enhance your chances of success.
For example, you can use some more advanced web scraper tools, such as:
- tls-client: A Go-based HTTP client that can mimic real JA3 fingerprints, including Chrome, Firefox, or Safari.
- curl-impersonate: A modified curl binary that impersonates the TLS and HTTP stacks of modern browsers.
Such tools can let you control the order of cipher suites and extensions, as well as your ALPN and HTTP2/2 vs HTTP/1.1 negotiation. But be warned – this is a rather technical aspect as you’ll need to determine what it is that’s triggering the TLS fingerprinting on the server side.
Use Proxies
You know we had to mention it. Proxies already serve a great purpose in web scraping – they can help bypass anti-bot detection measures, spoof appropriate geolocations and otherwise avoid getting a singular IP banned from overactivity.
It’s really no different here. Properly rotated proxies – be it rotating ISP proxies or rotating residential proxies, can help maintain anonymity and keep each IP unbanned in the long run.
Rotate Your Fingerprints
Rotating IPs alone won’t help you if you’re constantly sending the same fingerprint profile over and over. Servers with more strict or stringent requirements will catch on.
Instead, you should consider additional elements that can be rotated, such as your user agent, header and cookies. These will subtly change your client hello packet, helping to bypass TLS fingerprinting that would otherwise have blocked you already.
This does require some custom work, however. Such fingerprint randomization isn’t offered as an out-of-the-box package. By its nature, we don’t want it known and added to a public TLS library. But it is something a dedicated and highly-expertized team of web scraping experts could help you with 😉
Every Website is Different
TLS fingerprinting doesn’t have a “one and done” solution. Even across websites using the same base TLS fingerprinting protocols, there are always some adaptions. Each site might have its own database or criteria for allowing access.
We saw this earlier this year, for instance, when a 2025 Google update made JavaScript rendering a key requirement. It’s not a defacto requirement on every website, but it’s not a deal breaker for a web scraper on that particular search engine. But that’s just one example.
When focusing on one particular website for your needs, it’s worth focusing in on the exact specifics – how that site has been customized beyond basic TLS protocol.
And it’s Rarely Just About the TLS Handshake
TLS fingerprinting is just one part of the modern approach to anti-bot and anti-malware efforts. If you’re ethically scraping, TLS fingerprinting is certainly a key consideration, but it’s only one aspect.
In fact, there are a whole host of aspects to consider above and beyond the TLS connection. Your IP address and proxies are one such example, as are HTTP headers, browser behavior, JavaScript execution, cookie handling, session timing, and even interaction patterns

And it’s worth stating that ethical web scraping serves to work with the target website, rather than causing it to crash. Simply using a web scraper to such a scale that it impacts a website’s servers is akin to a DDoS attack, and websites respond to it like any other malicious clients.
Websites today use a layered approach to identify non-human traffic, combining network-level signals (like JA3/JA4, IP geolocation, ASN reputation) with application-level signals (like missing fonts, unusual screen sizes, or execution of headless-detection scripts).
If even one of those layers looks suspicious — say, a residential proxy with a perfect Chrome JA3 fingerprint but a curl-like user-agent or no JavaScript execution — it can be enough to trigger rate-limiting, or outright blocks.
Stay Undetected With Rotating Residential Proxies

In other words, while bypassing TLS fingerprinting is crucial, it’s a singular piece of the stealth puzzle. Effective, ethical scraping requires synchronizing all layers of your request stack to present a consistent, believable identity — from TLS handshake to DOM rendering.
This might be overwhelming, but we are talking from experience. In our experience helping clients with specific websites, we’ve found it effective to focus on the nuances of each site. We respect the terms of service that websites provide, and implement ethical web clients and scraping methods. We do this not only because it’s the right thing to do, but by respecting a website’s limits, we get better results in the long run.
Evolving Bot Protection & Adaptations
What’s more, websites aren’t static. Web owners work hard on network security and other anti bot measures that influence how the server responds to incoming requests. That’s why there’s no one magic web clients or easy gimmicks – if it was that easy, it would be just as easily countered.
When you’re scraping a website over a period of time, you’ll see changes in its defences as it responds to its own traffic. You need to identify and adapt to these changes in order to continue having access – and not adding to the malicious traffic that often drives such barriers in the first place.
TLS Fingerprinting & Web Scraping at the Enterprise Level
For large-scale scraping operations, staying undetected requires more than just clever code — it takes a full-stack strategy that mimics real users at every layer. Such enterprises know that websites aren’t just looking at TLS handshakes in isolation; they’re correlating them with browser behavior, IP history, session consistency, and more.
Consequently, successful scrapers don’t rely on simple libraries or basic header spoofing. Instead, they build systems that coordinate realistic TLS fingerprints, rotating browser identities, and high-quality proxy infrastructure into a seamless, human-like experience.
Here’s how enterprise teams manage to keep scraping at scale without getting blocked:
- ✅ Use full browser automation (Playwright, Puppeteer) to ensure matching TLS and JavaScript behavior
- ✅ Deploy custom TLS clients that can mimic JA3/JA4 signatures from real browsers
- ✅ Rotate not just IPs, but complete session identities: TLS fingerprint, user-agent, cookies, etc.
- ✅ Monitor target site responses to detect silent blocks, and fingerprint mismatches
- ✅ Maintain feedback loops to adapt quickly when defenses change or new fingerprinting methods emerge
And when a website has particularly strict TLS parameters, they contact web scraping experts.
In today’s landscape, scraping successfully means building trust — or at least the appearance of it — across every layer of your connection. The closer you get to looking like a real browser, the further you’ll get without resistance.
The information contained within this article, including information posted by official staff, guest-submitted material, message board postings, or other third-party material is presented solely for the purposes of education and furtherance of the knowledge of the reader. All trademarks used in this publication are hereby acknowledged as the property of their respective owners.



