The Ultimate Guide To Using PhantomJS For Web Scraping
Many people are looking into how to use PhantomJS for web scraping — and for a good reason. But first, you’ll need to understand headless browsers in general.
Headless browsers are web browsers without a graphical user interface (UI). Unlike traditional web browsers, they do not display web pages but provide an API that allows programs to interact with web pages. They are used to automate web testing, run scripts, and extract data from websites. They are also used for web scraping and other automated tasks.
Headless browsers are often faster and more efficient than traditional web browsers since they do not need to render the web page or download any images or other content.

What Is PhantomJs?

PhantomJS is one of these headless browsers that enables developers to automate web scraping tasks. It offers an alternative way of collecting HTML data from websites without manually crawling and scraping the content. PhantomJS is also lightweight, fast, and easy for experienced and novice developers to use. It includes native support for JavaScript libraries, such as jQuery, and CSS selectors for locating elements on a page and simulating user interactions like mouse clicks or keyboard inputs. It can also render pages in various formats, including PDFs.
It supports multiple web standards, so you can easily access AJAX-based content. Plus, there’s an extensive API that provides even more functionality when working with PhantomJS.
With all these tools at your disposal, you’ll be able to quickly gather data from any website without writing complex code or dealing with manual processes — this is one of the most significant selling points and why many people interested in web scraping want to learn how to use PhantomJS.
Scrape at Scale With Chromium
Playwright-compatible. Self-hosted. Built for real infrastructure.

OK, so Why PhantomJS?

When it comes to web scraping, the first step is obtaining the HTML code and then parsing it. Various tools can perform the first step.
PhantomJS, as a headless browser, doesn’t have a graphical interface. However, it can still imitate user actions — such as mouse clicks and form submissions. That makes it especially useful for obtaining HTML code from websites heavily reliant on front-end frameworks like React, Angular, or Ember since it can execute client-side JavaScript code. What PhantomJS can give you is the same HTML that a user would see in a normal browser where client-side codes are executed.
These sorts of dynamic websites don’t play well with more traditional formats of web scraping, which is why PhantomJS is even more appealing if you’re willing to learn it.
The Advantages of PhantomJS

One of the most obvious benefits of using PhantomJS is that headless browsers do not require graphics to be loaded to test or obtain data, making it theoretically faster than other web scraping alternatives. But that is only the tip of the iceberg.
You can scrape web pages without needing to interact with the user interface
Since headless browsers are used to access websites without interacting with the UI, they’re ideal for automation tasks. For example, you can use PhantomJS to automatically log into a website and scrape data from one page or multiple pages without needing manual input.
It’s fast and lightweight, perfect for fast and efficient scraping jobs
The speed and lightweight nature of PhantomJS make it the perfect tool for fast and efficient scraping jobs. It can process pages quickly, retrieving data in a fraction of the time other web scrapers take. This is especially useful if you need to scrape hundreds or thousands of pages in a short amount of time.
Additionally, its small footprint means there won’t be any strain on your system’s resources while scraping. This makes it ideal for servers where memory and processor usage are critical and ensures everything runs smoothly during long-running tasks without interruption.
Finally, because PhantomJS runs outside the browser environment, there isn’t anything slowing down page loading times or using up CPU cycles due to heavy rendering processes, unlike with traditional browsers such as Chrome and Firefox. This ensures maximum efficiency from start to finish.
Its JavaScript API gives you custom control over web page navigation
The JavaScript API also gives developers complete control over webpage navigation when writing custom scripts, so they can ensure their scraper will extract all relevant information from targeted sites.
Instead of relying on existing scrapers (which may not always work as expected), developers have complete control over the process, making PhantomJS invaluable for anyone looking to extract data from websites efficiently.
It supports various network protocols (HTTP/HTTPS/FTP/WebSocket)
PhantomJS supports a wide range of network protocols, making the tool incredibly versatile. In addition to HTTP/HTTPS and FTP, it supports WebSockets — an API for two-way communication between a browser and a server. This means you can interact with real-time data sources such as stock market APIs or social media feeds without employing separate tools and techniques for different web scraping tasks.
IP blocking or CAPTCHAs are circumvented
The support for various network protocols also makes PhantomJS effective for working with complex forms (as they’re rendered more simply) or websites that use simple layers of authentication before allowing access to certain information (such as financial records). This could include basic forms of IP blocking as well as CAPTCHA solving. PhantomJS can easily bypass any security measures put in place for bots quickly and efficiently while still being able to scrape the exact data points you need from each webpage.
In terms of use cases, PhantomJS displays excellent efficiency in:
- Taking screencaps: It is possible to automate taking and storing screenshots in the form of PNGs or JPEGs — even GIFs. This can be very useful for running tests on a website’s UI or user experience. For instance, you could use the command Phantomjs amazon.js to get images of rival products on the market or ensure your business’s product pages are displayed correctly.
- Web page automation: One of the primary benefits of PhantomJS is its ability to automate page operations and save time. Through commands like Phantomjs userAgent.js, code can be tested and evaluated for a given web page without opening a browser. This automation process is a major plus as it allows for quick and efficient development.
- Rapid testing: PhantomJS is a great asset for rapid website testing, much like Selenium and other scraping utilities. The lack of a graphical UI allows for quick-fire testing, with mistakes being identified and reported at the command line level. Integrating PhantomJS with various Continuous Integration (CI) systems will enable programmers to test their code before it goes live. This helps them quickly identify and repair broken code, resulting in more successful projects.
- Data collection and general network monitoring: PhantomJS can be used to keep track of network traffic and activity. Programmers can use it to acquire information, such as a web page’s performance, code alteration, stock price variations, and engagement metrics when scraping sites like TikTok, for example.
The Disadvantages of PhantomJS
0
Of course, it isn’t all rainbows and sunshine. There are downsides to using PhantomJS.
It’s a bit dated
PhantomJS has been around since 2011. While it is still one of the most popular technologies for web scraping, many newer options have arisen in recent years. One major downside of PhantomJS is that it does not support the latest web standards like ES6 (ECMAScript 6). If a website relies heavily on modern JavaScript coding techniques for its functionality or content delivery, PhantomJS may not properly interact with those elements.
For example, websites today built using React or Angular frameworks are often difficult to scrape with PhantomJS due to their reliance on advanced JavaScript features. This can limit what type of data can be retrieved when using this technology for web scraping purposes.
Its capabilities around authentication and cookies are actually limited
As mentioned earlier, PhantomJS is great at circumventing basic forms of IP blocking and avoiding CAPTCHAs. However, more advanced forms of security may be out of its pay grade. When it comes to websites with more aggressive and complex defenses, PhantomJS may be lacking.
Authentication and cookies are two of the most important components in web scraping. Many websites use sophisticated authentication protocols like OAuth 2.0 or SAML, which PhantomJS is not equipped to handle. Similarly, many sites employ complex cookie-based mechanisms for providing access control. These may also be inaccessible with PhantomJS due to its limited capabilities in this area.
As a result, web scrapers relying on PhantomJS may find themselves locked out of websites that require either authentication or cookies for access control measures.
Some versions have been reported as unstable
The instability of PhantomJS has been reported by many users and is especially prevalent in older versions. In some cases, such as when executing complex web scraping tasks with multiple simultaneous processes, there may be unexpected results or even crashes without any warning or error messages.
For example, say a web scraper implements an algorithm that employs a few independent threads to scrape data from different pages simultaneously while also regularly updating information on existing records stored in an external database (like MySQL or MongoDB). In doing so, it risks crashing due to memory leaks caused by bugs in versions of PhantomJS before version 2.1 (released October 2016). Such crashes can be difficult and time-consuming for developers trying to debug them before they cause further damage.
Scrape at Scale With Chromium
Playwright-compatible. Self-hosted. Built for real infrastructure.
Its UI-less nature can be exploited
Malefactors can take advantage of the fact that PhantomJS lacks a UI to carry out automated attacks because it is difficult to implement security protocols like CAPTCHA or two-factor authentication. This leaves websites vulnerable to malicious bot activity and other cyber threats.
For instance, attackers can launch Distributed Denial Of Service (DDoS) attacks with massive numbers of PhantomJS bots aimed at overwhelming web servers with requests to make them unavailable for legitimate users. They also use this technique when scraping sensitive data from websites such as credit cards or Social Security numbers, which are then sold on the dark web.
Another possible attack is “credential stuffing,” where hackers test millions of username/password combinations against login pages to steal credentials from unsuspecting victims who may have reused their passwords across multiple online accounts.
It’s challenging to use for full-cycle and end-to-end testing
Full-cycle and end-to-end testing, as well as functional testing, can be difficult to carry out with PhantomJS. For example, it cannot detect changes in page elements that occur after an AJAX call or a JavaScript event. Similarly, because it does not render the HTML code the same way a browser would, features like dynamic content loading may not be detectable by PhantomJS.
Furthermore, automated tests for user interactions, such as mouse clicking and keyboard input, cannot be performed with this technology since there is no UI on which they can take place. All of these limitations make full cycle/end-to-end and functional testing considerably more challenging.
Alternatives to PhantomJS for Web Scraping

After weighing these pros and cons, you may want to better understand your alternatives, especially for web scraping at scale. PhantomJS is ideal for quick and dirty web scraping jobs, but its limitations can even turn its advantages against it. This lack of reliability at scale means that other options should be explored and used in conjunction with PhantomJS web scraping, but they also have their downsides.
Packaged data sets that are ready-to-use
Data sets are pre-assembled packages of data that can be supplied to algorithms/teams right away. This information usually consists of details from one source and is supplemented by similar sites on the web (for example, details on items from a range of vendors and different e-commerce marketplaces). These data sets can be updated regularly to ensure that all the information is up to date. The best part is that you don’t have to spend time and resources gathering the data, so you can focus on performing data analysis and delivering value to customers.
The biggest limitation of packaged data sets is that they may not be as comprehensive or up-to-date as needed. Moreover, they are limited to the data from one source and its counterparts, so you won’t have access to additional information outside of what was previously provided. Additionally, depending on your use case, there might be restrictions regarding how you can use the data due to copyright issues or other privacy concerns.
Fully automated web scraping solutions
Web Scraper IDEs (Integrated Developer Environments) offer a complete, automated solution for data harvesting. No coding or hardware is required. The process is simple:
- Choose the website to scrape.
- Set the frequency (real-time or periodic).
- Decide on the output format (typically JSON, CSV, HTML, or XML).
- Have the data delivered to a location of your choice (for instance: webhook, email, a cloud solution, or API).
This makes it easy for businesses to participate in data collection without all the associated technical headaches.
On the other hand, web scraper IDEs may not be able to handle complex websites that require advanced scraping techniques, such as those with dynamic content or AJAX-driven pages. Additionally, the data output can only be in specific formats — locked into the capabilities of the IDE provider.
There’s also the practical consideration of cost. An IDE is a full-feature infrastructure, and you may not consistently need something that comprehensive at your current scale.
Proxy-based web scraping
Using proxies for web scraping can allow users to make countless simultaneous requests. This method can help one get around restrictions like rate limits or geo-blocks. Companies can employ country/city-specific mobile and residential IPs/devices to route data requests and collect more precise user-facing data, including competitor costs, ad campaigns, and Google search results.
But proxy-based web scraping can be costly and time-consuming to set up due to the need for multiple IPs or devices. Additionally, an incorrect configuration could lead to a lower success rate with data requests being blocked or throttled by target websites. You will also fundamentally be at the mercy of proxy providers and the quality of the servers they provide.
If you’re web scraping with PhantomJS, you will likely need to use proxy servers. Proxies can help mask your IP address and prevent detection, allowing your scripts to run smoothly without being blocked. They can also be used for collecting data from multiple geographic locations or quickly making requests at scale.
Using Proxies for Effective Web Scraping

As mentioned earlier, a proxy functions as a go-between for your PC and the internet. When you submit a query to a website, the proxy will take the request, forward it to the site, and then deliver the response back to you.
Utilizing a proxy when web scraping has several advantages. Manually transferring data from each web page is a big waste of time and resources, particularly when there are scraping tools that can store data and requests. But website hosts are aware of a scraper’s effectiveness and can detect it when it sends multiple requests in a short time span. They may block the IP address to stop further actions, but a proxy can help bypass this restriction.
Regardless of why you use proxies, websites are generally guarded against proxy-powered scrapers because such tools can flood servers with traffic or even be utilized by malicious actors to carry out DDoS attacks. This is why reliable proxies are a must-have, especially from providers that can offer additional features such as proxy rotation and similar functions.
Ethical proxy use
When it comes to web scraping or acquiring panel data, Rayobyte is the perfect proxy provider. We provide residential proxies, ISP (Internet Service Provider) proxies, and data center proxies — ensuring that you can find the ideal match for your requirements. Our company is highly professional and ethical, so you can be sure you are in safe hands.
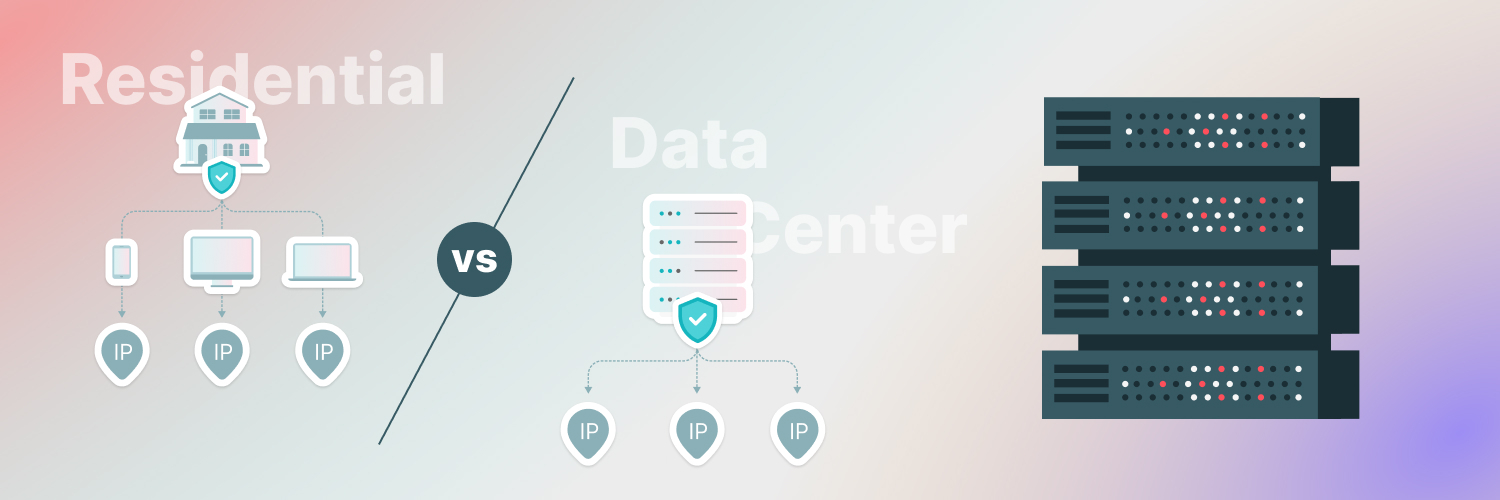
Obtaining residential proxies is often the best strategy for web scraping. These proxies provide IP addresses assigned to people by their ISPs, and we make sure to source only the finest residential proxies and work hard to maintain minimal downtime.
If you’re after more speed, data center proxies are worth considering. These proxies can get your data to its destination quicker by routing traffic through data centers. Though this may mean fewer unique, nonresidential IP addresses, these proxies still offer great value for money.
ISP proxies are linked to an ISP but located in a data center, thus combining the swiftness of a data center and the trustworthiness of an ISP.
Final Thoughts

This primer on PhantomJS may not delve into all its complexities, but it’s a starting point to show you how to use PhantomJS effectively for your web scraping needs and highlight some of the other options available to you.
Using the right web scraping approach is key to unlocking highly valuable insights from various sources. What matters is that you find the approach that suits you best and the infrastructure to enable that approach.
This is where a reliable proxy server provider comes in. Rayobyte offers excellent proxy servers and additional tools, such as Rayobyte’s Web Scraping API, to automate the bulk of your web scraping workload. Explore our proxy solutions now.
Scrape at Scale With Chromium
Playwright-compatible. Self-hosted. Built for real infrastructure.
The information contained within this article, including information posted by official staff, guest-submitted material, message board postings, or other third-party material is presented solely for the purposes of education and furtherance of the knowledge of the reader. All trademarks used in this publication are hereby acknowledged as the property of their respective owners.